Vowels and Pseudo-Vowel Consonants
The majority of phonemes used in English are voiced sounds caused by a periodic, impulsive airflow. The glottis operates as a "trapdoor" mechanism to regulate the flow of air over the vocal chords. Tension holds the glottis closed until air pressure in the trachea reaches a critical threshold and forces the glottis open. With the sudden flow of air the pressure drops below the level necessary to hold the glottis open; the glottis closes to begin another cycle. Variations in diaphragm pressure and glottal tension alter the period of the cycle to determine the fundamental pitch of the sound produced. [3]
The vocal tract resonates in response to the periodic airflow at formant frequencies. Formant frequencies distinguish one voiced phoneme from another and are controlled by tension in the vocal chords. Voiced sounds are further filtered by the actions of the nasal cavity and the mouth. Vowels constitute most of the voiced sounds, although several "near-vowel" consonants are also generated in this way.
We model the glottal mechanism as an impulse train with a constant frequency of 120 Hz, producing quite monotone voiced sounds. A more sophisticated speech synthesizer could alter the impulse period from sound to sound and during sounds to convey accent, emotion, an interrogative sense, etc., to produce more realistic speech. In addition, more detailed models of the glottal impulse (such as Rosenburg's model) may be used for a more accurate representation of the effect. [1]
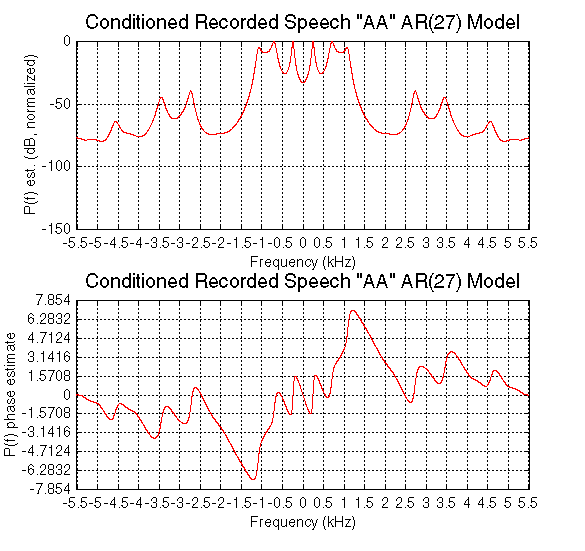
We model the vocal tract and other filtering of the glottal impulse as an autoregressive (AR) filter created specifically for each phoneme. We fitted an AR model to sampled utterances of the voiced sounds and took the resulting all-pole filter to represent the effects of the vocal tract. We selected AR methods for their ease of implementation and because the vocal tract is characterized by resonances rather than frequency nulls. The formant frequencies are evident as peaks in the transfer functions of our filters.
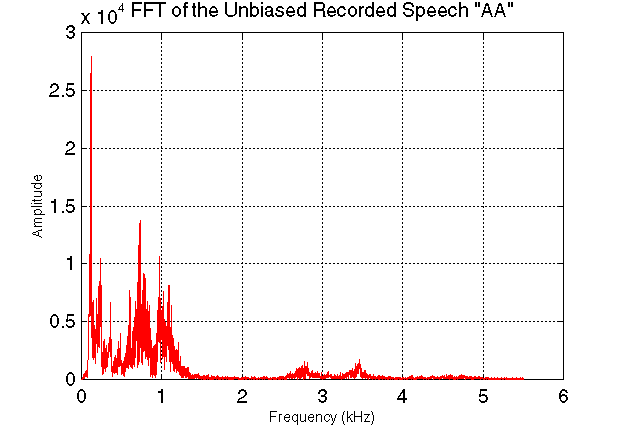
A large additional peak is evident at approximately 120 Hz in the spectrum of each of our sampled utterances, representing the fundamental frequency of the glottal impulse mechanism. This peak provides the inspiration for our selection of fundamental pitch. Furthermore, the literature indicates that the average fundamental pitch for male speakers is in the range of 120 Hz; the average female fundamental pitch is about 100 Hz higher. [2, 4] (This plot is labelled "unbiased" because the DC bias caused by our format conversion to use MATLAB has been removed.)
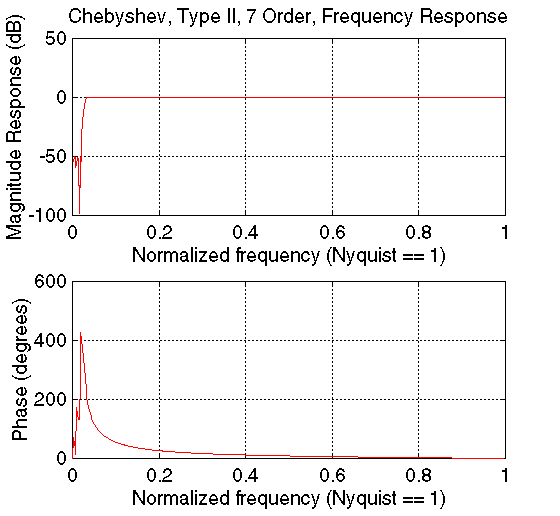
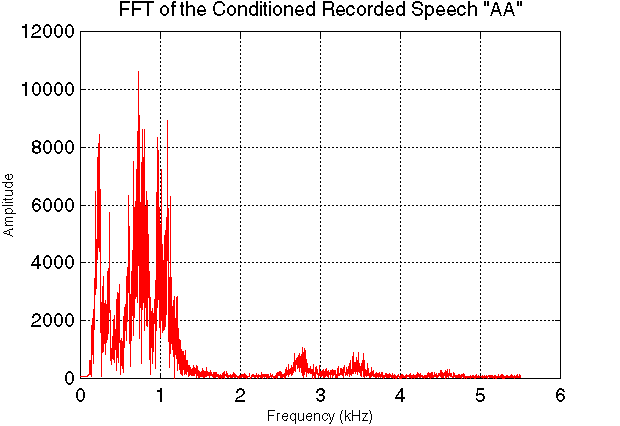
To create our models, we conditioned our sampled utterances with the Chebyshev filter shown below (selected for its sharp transition and flat passband response) to eliminate the glottal impulse peak (see below). (We also subtracted the sample mean to remove the DC bias resulting from conversion between the .wav and .au signal formats.) We then fitted an AR (Yule-Walker) model to the conditioned signal and drove this filter with a 120 Hz impulse train.
Timothy D. Dorney and Robert H. Sparr
Electrical and Computer Engineering Department, Rice University
April 1996