![[Rice University]](http://www.staff.rice.edu/images/staff/branding/shield.jpg)
Using PCA for Text Analysis
This is a continuation of our discussion of Preparing Text Data for PCA Analysis.
We will be using the PCA analysis class that comes with the matplotlib library: matplotlib.mlab.PCA documentation
To use Python's PCA analysis capabilities, include the following import statements at the top of your code:
from matplotlib.mlab import PCA # gets the PCA class import numpy as np # gets some useful functions such as special arrays, dot-product, etc. import numpy.linalg as npla # gets some specialized linear algebra functions such as vector length (normalization), etc.
Classes in Python
PCA in Python is an example of new type of Python entity called a "class". A class is like a recipe which is then used to create many objects, which is a data structure that not only holds information ("state"), which can sometimes be accessed as "attributes", but also includes associated functions, called "methods" that perform various operations based on the information held by the object. Classes and objects form the nucleus of object-oriented programming, which is arguably one of the most important and widely used programming paradigms in the world today.
Those students who have taken Java or C++ may have encounterd classes already in those languages -- this is the same idea, though the syntax is slightly different. Here is a Java-based discussion of objects and classes.
Object-oriented programming is a rich and deep subject that takes years of study and practice to master. Continue on in CS at Rice and you will encounter it in classes such as Comp215, Comp310, Comp402, Comp410, Comp411 and Comp415.
Object Construction from a Class
The general Python syntax to make an object (technically, an object reference) from a given class is very simple:
aVariable = ClassName(param1, param2, etc)
- aVariable will refer to an object "instance", the specific object being made right now.
- ClassName is the name of class being used to make the object, e.g. "PCA" for out work below. Technically, the class name with the parentheses is referred to as the class's "constructor".
- param1, param2, etc are input parameters that supply initial data to initialize this specific object. Below, we will be providing the data points we prepared as the input parameters to the constructor.
PCA's constuctor takes an array ( a numpy array -- Be sure to read the note about using numpy arrays and the PCA constructor) of data points, easily derived from the data point matrix we made previously.
Example object construction using PCA
Accessing Attributes
Attributes allow the programmer to access information that is held inside a particular object. Except in special situations, attributes are always used with respect to variables that refer to objects, NOT with regards to the class itself. This is VERY common mistake!!
In general, the Python syntax to access an attribute is simply to use a dot (period) after the object's variable name followed by the name of the desired attribute:
x = AClassName(params) # x now refers to an object instance of AClassName y = x.attributeName # y now refers to the info accessed by attributeName.
PCA objects have 8 attributes that can be accessed to retrieve various aspects of the PCA processing of the data points that were given to its constructor.
Example:
from matplotlib.mlab import PCA import numpy as np myPCA = PCA(np.array(topValMatrix)) # topValMatrix is a list-of-lists type matrix of data points that needs to be converted into a numpy array for PCA's constructor. means = myPCA.mu # means now refers to a list of the mean values across all the data points for each measurement axis. xformedDataPts = myPCA.Y # xformedDataPts now refers to a matrix of data points represented in terms of the principle component axes.
Using Methods
Methods allow the programmer to process data with respect to the information carried inside an object. Like attributes, except in special situations, methods are always used with respect to variables that refer to objects, NOT with regards to the class itself. This is VERY common mistake!!
The general syntax for calling a method is very similar to the syntax for accessing an attribute (technically, in Python, a method is an attribute!):
x = AClassName(params) # x now refers to an object instance of AClassName y = x.aMethod(inp1, inp2, ect) # y now refers to the return value from running x's aMethod method with the input parameters, inp1, inp2, etc.
Example:
from matplotlib.mlab import PCA
import numpy as np
myPCA = PCA(np.array(topValMatrix)) # topValMatrix is a list-of-lists type matrix of data points that needs to be converted into a numpy array for PCA's constructor.
xformedUnknownDataPt1 = myPCA.project(unknownDataPt) # xformedUnknownDataPt1 now refers to a vector of the given unknownDataPt vector, represented in the
# principle components axes defined by topValMatrix.
xformedUnknownDataPt2 = myPCA.project(unknownDataPt) # xformedUnknownDataPt2 now refers to a vector of the given unknownDataPt vector, represented in the
# original measurement axes but translated to the center of the cluster and scaled by the standard deviations from topValMatrix.
Analyzing an Unknown Text Using PCA
Finally! We had to build up a lot of infrastructure to get to this point but with that infrastructure in place, we have a lot tools at our disposal that we can use to explore the analysis of an unknown text with respect to our known data points. At this point, we have a PCA object that was built from the known data points. Now we will use its capabilities to help us analyze unknown texts by seeing how an unknown text's data point compares to the cluster formed by the known texts.
If one selects 3 of the many measurement or principle component axes, a plot of the data points can be made (see the How-To's web page on plotting for info on creating 3-D plots):
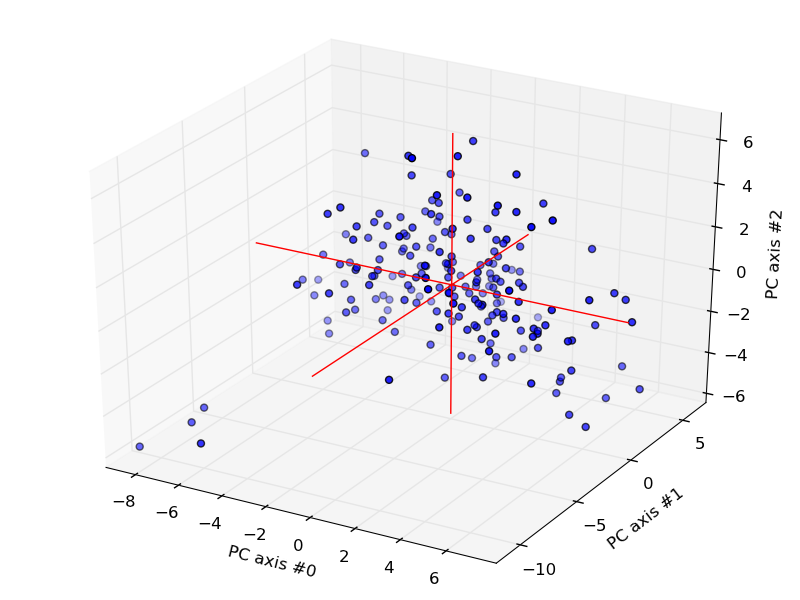
Scatter plot of the Complete Works of Shakespeare (minus Hamlet and All's
Well That Ends Well)
in terms of the first 3 principle component axes.
Notice how the the data is basically clustered around the origin, the center of the cluster, which is also the origin for the PC axes. The cluster is close to spherically shaped because the dimensions have been scaled (normalized) by the standard deviations, thus reducing ovoids into spheres. An interesting question here is, what are those 4 outliers in the data?
We do have to do a little bit of prep to the unknown text however, to generate a new data point in the same space as the PCA data points:
- Read the unknown text in and parse it into words and create a normalized word/tuple frequency dictionary.
- Use that dictionary and the defining word keys (the ones that define the measurement axes) to create a standardized dictionary and thus a standardized data point vector of normalized counts.
It should be pointed out that at this juncture, we have a data point vector, just like the ones that we used to create the PCA object in the first place. For a scientist, being able to show evidence that your analysis makes sense is paramount. The analysis from this point on could continue with either known or unknown data points! Checking results by using known data points is great way to reassure oneself that the analysis makes sense.
In short, at this point, we can either use the PCA object's project() or center() methods to transform the test data point (i.e. either the unkknown or a known data point) into the PCA's cluster-centered space and see how that new point compares against the exisitng data points in the cluster. The job of the scientist here is to come up with a good comparison technique that clearly measures how likely an unknown text is from the same author as the known texts. Don't forget that there are also other variables to tweak, such as the word tuple length, the number of top words to keep as the defined axes, the text chunk size, etc.
Some possibilities:
- Measure the length of the projected test data point -- this is its distance from the center of the cluster in the PC axes. (numpy.linalg.norm(v) will give you the length of a vector v.
- Measure the average of (absolute value of) the centered component along each measurement axis. The known data points have an overall average value of 1 for this comparison (see the docs for the PCA.a attribute).