
|
|
Comp202: Principles of Object-Oriented Programming II
|
This tutorial will lead you through the process of developing a recursive descent parser to parse simple infix arithmetic expressions and build the corresponding parse trees.
You are given the source code of a parser with a few of the factory classes stubbed out. Your task is to complete the missing code and obtain a working parser to parse simple arithmetic expressions in infix format as described by the following.
Click here to download the partially stubbed out source code.
Click here to download the demo.
Click here to download a bunch of sample input files.
To run the demo: java -jar rdp.jar
We shall write a program to read in from a text file a simple arithmetic expression in in-fix format, such as "abc + 45 + x + y", and build the corresponding parse tree. We shall restrict ourselves to arithmetic expressions containing integers, strings (representing variables) and addition. The syntax of such arithmetic expression can be expressed as a grammar with the following rules.
E ::= F E1
E1 ::= E1a | Empty
E1a ::= + E
F ::= F1 | F2
F1 ::= num
F2 ::= id
Here is how the above grammar generates the string "abc + 45".
E -> F E1 // E is the start symbol and has only one rule: E ::= F E1
-> F2 E1 // Apply the rule F ::= F2
-> id E1 // Apply the rule F2 ::= id
-> id E1a // Apply the rule E1 ::= E1a
-> id + E // Apply the rule E1a ::= + E
-> id + F E1 // Apply the rule E ::= F E1
-> id + F1 E1 // Apply the rule F ::= F1
-> id + num E1 // Apply the rule F1 ::= num
-> id + num Empty // Apply the rule E1 ::= Empty
-> abc + 45 // the lexeme of id is "abc" and the lexeme of num is "45"
The above derivation of the input string "abc + 45" from the grammar rules can be represented by a tree structure called the parse tree as follows.
E
|
------------------------------------
|
|
F
E1
|
|
F2
E1a
|
|
id
---------------
"abc"
|
|
+
E
"+"
|
----------
| |
F E1
| |
F2 Empty
|
num
"45"
To read a Text input file, we use a scanner called Tokenizer3.java given the provided source code. Each time we call on the tokenizer to get the next token (getNextToken()), it will return an AToken object as defined by the following.
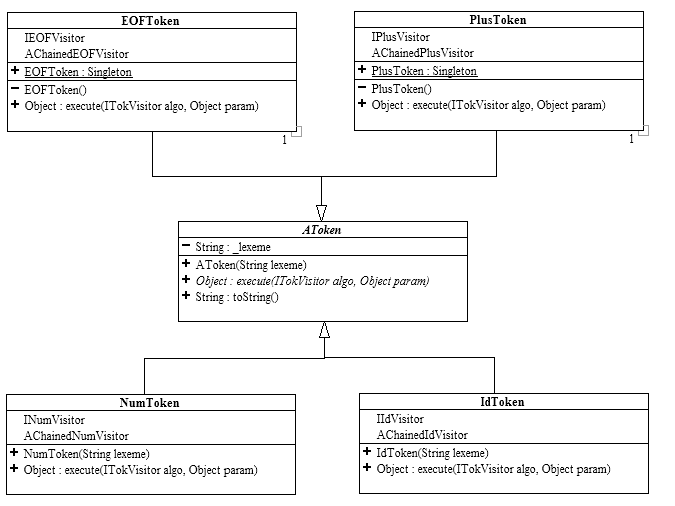
Each token type knows how to execute an ITokVisitor (see below) and defines its own specific visitor that is a subtype of ITokVisitor. When a concrete host token accepts a visitor using AToken.execute(…), it checks if that visitor is its own specific visitor and calls the host-specific method of the visitor if this is the case, otherwise it calls the default case method. For instance, in Listing 1 , the NumToken host checks if the visitor, algo, is of type INumVisitor. If it is, the host-specific method of the visitor, numCase(…), is called, otherwise the default case method, defaultCase(…), is called.
When a non-terminal symbol has more than one rule associated with it (for example F has two rules associated with it), the visitors to parse each of the rules are chained together using the chain of responsibility design pattern in order to allow the current token to pick out the correct visitor to execute. The fact that the grammar in question is LL(1) guarantees that there is exactly one visitor in the chain that will match for the current token.
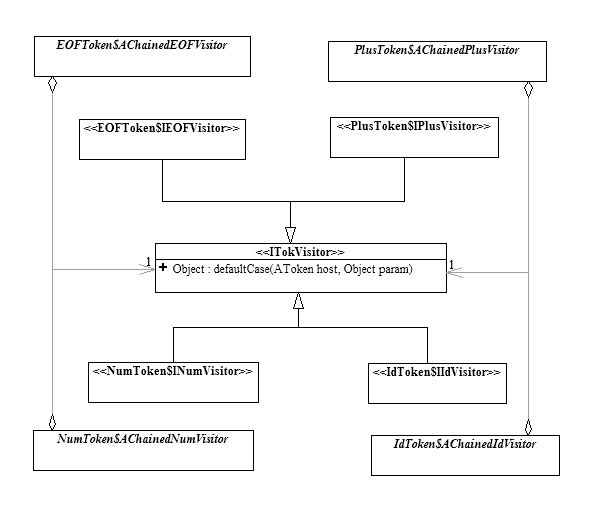
All the above visitors are defined as nested classes/interfaces inside of their respective token classes. For example, INumVisitor and AChainedNumVisitor are defined inside of NumToken.
The above grammar can be modeled as a system of classes/interfaces as follows. A rule that is a sequence of symbols like that of E, is represented by composition ("has-a"). When a non-terminal has more than one rule, it is represented as an interface whose concrete implementations are the classes on the right hand side of each of the rules..
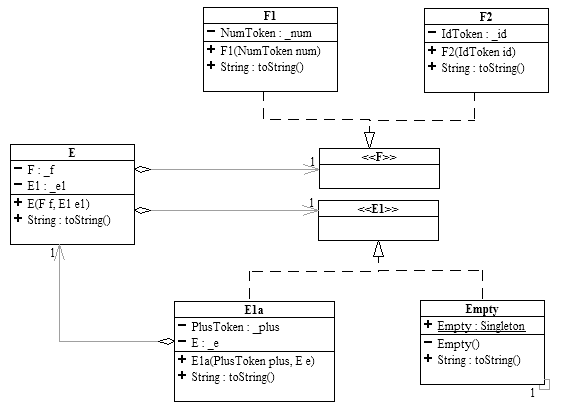
In recursive descent parsing (RDP), we use a "tokenizer" to scan and "tokenize" the input from left to right, and build the parse tree from the top down, based on the value of the tokens. Building a parse tree from the top down means building it by first looking at the grammar rule(s) for the start symbol E and try to create the object that represents E. The task of building E is called "parsing E" and is to be carried out by an appropriate token visitor.
We can see from the above diagram that in order to parse E, we need to know how to parse F and E1.
Writing the concrete visitors to parse each of the non-terminal symbols will require, in general, performing a global analysis looking deeper than necessary into the grammar structure. One must analyze the details of the grammar to the level of knowing all possible tokens at that stage. This analysis may require one to look beyond the immediate relationships a class may have with any other classes. For instance, to find the possible tokens that could be the start of an E term, one must look down to the F term. However, the code to process an E term should only be concerned with the fact that an E term is composed of a F term and an E1 term, and should not be coupled to the internal nature of the F, E1 or any other terms. Likewise, when parsing a branch, such as F, one must create the union of all the visitors that parse the branch’s subclasses.
To remedy this problem, one must
re-think the instantiation process of the visitors.
In particular, in order to decouple the construction of the visitor for
one term from the details of other terms, one must abstract and encapsulate the
construction process. This is done
by the abstract factory design pattern. Using
factories to instantiate the parsing visitors
·
enables each term to be decoupled from any other term by hiding
the instantiation details.
·
enables the construction of the union of visitors by chaining,
which is used to implement branches.
·
enables the lazy construction of already installed visitors which
is needed to create circular relationships.
Each non-terminal symbol (and
its corresponding class) is associated with a factory that constructs its
parsing visitor. All factories
adhere to a basic factory interface which provides the methods to instantiate
the parsing visitors. For
convenience, all the factories are derived from an abstract factory, ATVFactory,
which provides access to the tokenizer.
Below is the UML class diagrams for the factories involved.
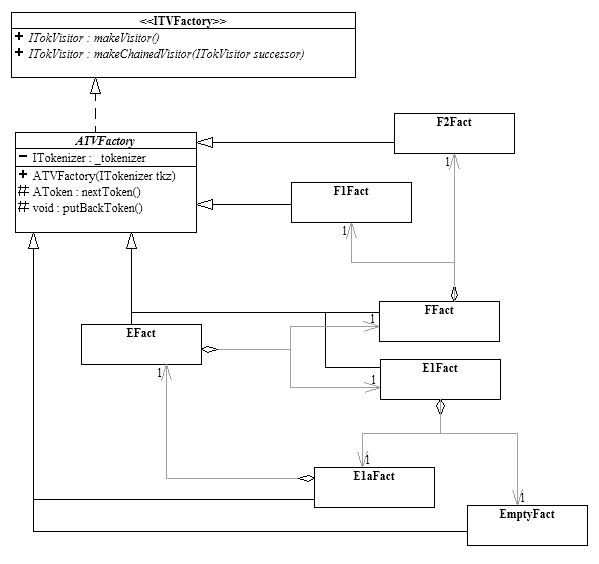
The factories for sequence terms (e.g. E and E1a) are initialized with the factories of their composed terms. The actual creation of the visitors is delayed until the first call to makeVisitor() or makeChainedVisitor(), since only then is it guaranteed that all factories have been created and circular references can safely be established. The initializer object _initializer, which performs this lazy construction, is instantiated anonymously and replaces itself with a no-operation to ascertain it is executed only once. This is an example of the state design pattern.
The result is that instead of constructing the parsing visitors directly, one now constructs the parsing visitor factories as shown in the above UML class diagram. Note that the object structure of the factories matches that of the grammar object model shown earlier, except that all the factory-factory relationships are compositional. Each factory’s construction only requires the factories of those terms it is directly related to, either by composition or by subclass. One thus need only know the grammar one level at a time, no global knowledge of the grammar is needed. This decoupling of the grammar terms makes the system very robust with respect to changes in the grammar.
To start parsing, we simply ask the top-level factory, EFact, to make its visitor and apply that visitor to the first token, as illustrated by the following code fragment from RDPFrame.java.
import parser.*;
import javax.swing.*; import java.awt.*; import java.awt.event.ActionEvent; import java.awt.event.WindowEvent; import java.io.FileNotFoundException;
public class RDPFrame extends JFrame {
/**
* a bunch of stuffs stubbed out...
*/
/**
* Make parser.
*
* @throws FileNotFoundException thrown if file is not found
*/
protected void makeParser() throws FileNotFoundException {
tok = new Tokenizer3(inpFileTF.getText());
E1aFact e1aFac = new E1aFact(tok);
eFac = new EFact(tok,
new FFact(tok, new F1Fact(tok), new F2Fact(tok)),
new E1Fact(tok, e1aFac, new EmptyFact(tok)));
e1aFac.setParseEFactory(eFac);
System.err.println("Parser Factory = " + eFac);
}
/**
* Parse file.
* @param e action event
*/
void parseBtn_actionPerformed(ActionEvent e) {
try {
makeParser();
ITokVisitor parser = eFac.makeVisitor();
System.out.println("Parser visitor = " + parser);
Object result = tok.getNextToken().execute(parser, null);
System.out.println("Result = " + result);
outputTA.setText(result.toString());
}
catch (Exception e1) {
// code elided...
}
}
}
You are given the code for EFact, E1Fact, EmptyFact and FFact. Use them as a guide to complete the rest of the factories: F1Fact, F2Fact, E1aFact.
Last Revised Thursday, 03-Jun-2010 09:52:24 CDT
©2006 Stephen Wong and Dung Nguyen