Introduction
This lecture describes an important parsing technique called "recursive descent parsing". It leads you to the process of developing such a parser to parse scheme-like arithmetic expressions and build the corresponding abstract syntax trees. It makes use of the StreamTokenizer discussed in lecture 27 and the results from homework #3 on abstract syntax trees.
Click here for the paper on recursive descent parsing by D.X. Nguyen and S. B. Wonng.
We shall write a program to read in from a text file scheme-like arithmetic expressions in pre-fix format, such as (* 3 (+ 4 5)), and build the corresponding abstract syntax tree (AST):
*
/ \
3 +
/ \
4 5
Once the AST is built, one can then traverse and evaluate it, as done in Homework #3 (download the solution)! We shall restrict ourselves to arithmetic expressions containing integers, strings (representing variables), and binary operations such as addition and multiplication. The syntax of the Scheme-like arithmetic expression can be expressed as a "grammar" with the following rules.
|
Scheme Arithmetic Expression Grammar Rules |
Description |
| E :: Leaf | BinOp | An expression E is either a Leaf or a
BinOp. The notation is the left column cell is a short hand for two
rules:
|
| Leaf :: VarLeaf | IntLeaf | A Leaf is either a VarLeaf or an IntLeaf There are actually two grammar rules here (see above cell). |
| VarLeaf :: id | A VarLeaf is an id, where id is a token representing a variable. |
| IntLeaf :: int | An IntLeaf is an int, where int is a token representing an integer. |
| BinOp :: AddOp | MulOp | A BinOp is either an AddOp or a MulOp. There are actually two grammar rules here. |
| AddOp :: ( + E E ) | An AddOp is a left parenthesis token, followed by a plus token, followed by an expression E, followed by another expression E, followed by a right parenthesis token. |
| MulOp :: ( * E E ) | An MulOp is a left parenthesis token, followed by a star token, followed by an expression E, followed by another expression E, followed by a right parenthesis token. |
An example for such an expression is: (* 34 (+ xyz 7)), where
In the above grammar rules,
The above grammar is an example of what is called an context free grammar (CFG). In general, a CFG is a quadruple (NT, T, R, S) where
Grammars are used to define the syntax of finite sequences of tokens. The set of all finite sequences of tokens that conform to the given grammar rules is called the language generated by the given grammar. Parsing a finite sequence of tokens according to a grammar means determining whether or not this token sequence (also called sentence) conforms to the syntax defined by the grammar. We shall implement a special parsing technique called "recursive descent parsing" (RDP) that works for a restricted set of grammars. The above grammar for prefix Scheme like expressions is one such grammar.
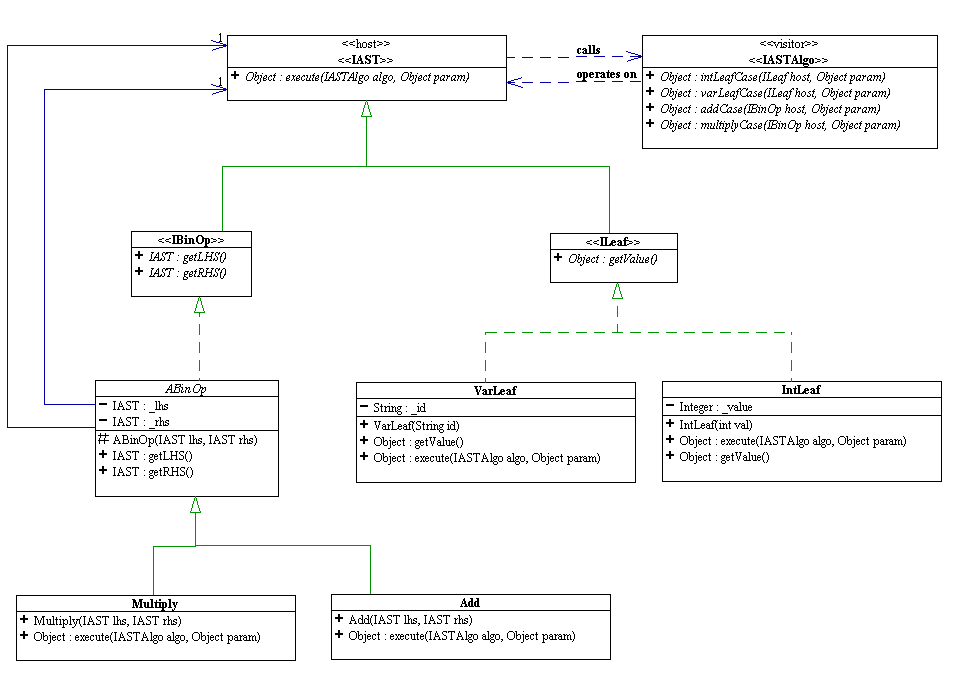
Here is again the class diagram of the abstract syntax tree that represents the Scheme-like arithmetic expression described by the above grammar. Note how each of the classes corresponds to a non-terminal symbol in the grammar.
The manufacturing of the above abstract syntax tree (AST) can be thought of a factory method, makeAST(), of some abstract factory, IASTFactory. How the AST is created is a variant as there are many ways to parse the input stream.
In RDP, we use a "tokenizer" to scan and "tokenize" the input from left to right, and build the AST from the top down, based on the value of the tokens. Building an AST from the top down means building it by first looking at the grammar rules for the start symbol E and try to create an AST that represent E.
As we look at the grammar rules for the start symbol E in the above, we can see that in order for RDP to make an E AST (makeAST), it needs to know how to make a Leaf AST (makeLeaf) and a BinOp AST (makeBinOp).
Here is some pseudo-code.
makeAST():
makeLeaf():
makeIntLeaf(): create the IntLeaf directly. To create an IntLeaf, we need to have the int token. Thus, makeIntLeaf() will need a token as a parameter.
makeVarLeaf(): create the VarLeaf directly. VarLeaf will need a token as parameter.
makeBinOp():
makeAddOp():
makeMulOp(): analogous to makeAddOp().
In short, a RDP
Usually, parsing only involves checking for the syntax of an input expression. However, in our case, we decide to build the abstract syntax tree directly as we parse.
public class RdpASTFactory implements IASTFactory {
private ITokenizer _tokenizer:
public RdpASTFactory(ITokenizer tokenizer) { _tokenizer =
tokenizer;}
public IAST makeAST() { // etc...}
private IAST makeLeaf() { // etc...}
// other (private) factory methods, etc.
}
The above pseudo-code suggests designing a union of token objects coupled with visitors, and an abstract tokenizer class that knows how to get the next token.
public abstract class AToken {
protected String _lexeme;
protected AToken(String lex) { _lexeme = lex; }
public String toString() { return_lexeme;}
public abstract Object execute(ATokVisitor v, Object inp);
}
public class IdToken extends AToken{
// constructor, etc.
public Object execute(ATokVisitor v, Object inp) {
return v.idCase(this, inp);)
}
}
public abstract class ATokVisitor {
/**
* This is the case when the host is a concrete IdToken.
* Throws an IllegalArgumentException as default behavior.
* @param host a concrete IdToken.
* @param inp the input needed for this ATokVisitor to perform
its task.
*/
protected abstract Object defaultCase(AToken host, Object inp) {
// In many concrete cases, the code
will look something like:
// throw new
IllegalArgumentException("Wrong token!");
}
public Object idCase(IdToken host, Object inp) {
return defaultCase(host, inp);
}
// etc..., a method for each concrete token case.
}
public interface ITokenizer (
public AToken getNextToken();
}
public class StreamTokWrapper implements ITokenizer
{
private StreamTokenizer _st;
// constructor and methods, etc...
}
Dung X. Nguyen
revised
09/02/2004