Summary: An overview of recursion and recursive algorithms from an object-oriented perspective.
Recursive Data Structures
A recursive data structure is an object or class that contains an abstraction of itself.
In mathematical terms, we say that the object is "isomorphic" to itself. The basic embodiment of a recursive data structure is the Composite Design pattern. Recursive data structures enable us to represent repetitive abstract patterns. In such, they enable us to generate or represent complexity from simplicity.
Characteristics of a recursive data structure:
- Abstract representation : Since the actual total structure of the data is not known until run-time, the data must be represented by an abstraction, such as an abstract class or interface.
- Base case(s) : These represent the "end" of the pattern. They are the termination point(s) of the data structure.
- Inductive case(s) : These represent the on-going, "interior" portion of the repetitive pattern. They embody the ability to represent the data structure as a a simple connection between abstractly equivalent entities.
Recursive data structures are arguably the most important data structure in computer science as they are able to represent arbitrarily complex data. Indeed, if one looks across all the sciences, one sees that one of the fundamental modeling tools used is to attempt to
Recursive Algorithms
In order to process a recursive data structure, it makes sense that any such algorithm should reflect the recursive nature of the data structure:
A recursive algorithm is a process that accomplishes its task, in part, by calling an abstraction of itself
Recursion is thus a special case of delegation.
In light of the above definition, it is not surprising that recursive algorithms and recursive data structures share common characteristics:
Characteristics of a recursive algorithm:
- Abstract representation : Since the actual total process needed to process the recursive dataastructure of the data is not known until run-time, the algorithm must be represented by an abstraction, such as an abstract method (this is not the only way).
- Base case(s) : These represent the "end" of the algorithm. They are the termination point(s) of the algorithm.
- Inductive case(s) : These represent the on-going, "interior" portion of the algorithm. They embody the ability to process the recursive data structure by calling the same abstract process on the composed elements of the structure.
The similarity between recursive algorithms and recursive data structures is because in an OO system, the structure drives the algorithm. That is, it is the form of the data structure that determines the form if the algorithm. In an OO system, objects are asked to perform algorithms as they pertain to that object--that is, an algorithm on an object is a method of that object. The data has the behavior. The data is intelligent. This is in contrast to procedural or functional programming, where data is handed to the behavior. That is, stand-alone functions are used to process non-intelligent data. (Caveat: With all that said, in more advanced designs, we will show the algorithm can be decoupled from its data structure and thus be removed as a method of the data. This will not change the above principles however.)
The basic notions of creating a recursive algorithm on a composite design pattern structure are
- The abstract superclass or interface of the data structure has the invariant abstract behavior of being able to perform the algorithm (and thus the computations associated with it).
- Each concrete subclass has its own implementation of that abstract behavior, which is just the variant part of the algorithm that pertains to that particular subclass.
This is the Interpreter Design pattern. Notice that no checks of the type of data being processed (e.g. base case or inductive case) are necessary. Each data object knows intrinsically what it is and thus what it should do. This is called "polymorphic dispatching" when an abstract method is called on an abstract data object, resulting in a particular concrete behavior corresponding to the concrete object used. In other words, we call a method on a list, but get the behavior of an empty list if that what the list is, or we get the behavior of a non-empty list if that is what the list is.
In order to prove that a recursive algorithm will eventually complete, one must show that every time the recursive call is made, the "problem" is getting "smaller". The "problem" is usually the set of possible objects that the recursive call could be called upon. For instance, when recursively processing a list, every call to the rest of the list is calling on a list that is getting progessively shorter. At times, one cannot prove that the problem is definitely getting smaller. This does not mean that the algorithm will never end, it just means that there is a non-zero probability that it will go on forever.
One of the key aspects of a recursive algorithm is that in the inductive case, the inductive method makes the recursive call to another object's method. But in doing so, it has to wait for the called method to return with the needed result. This method that is waiting for the recursive call to return is called a "pending operation". For instance, at the time the empty list (base case) is reached during a recursive algorithm on a list, every non-empty node in that list has a pending operation.
EXAMPLE 1: Animated Recursion Demo
Below is an example of generally what is happening in four linked objects during the call to the recursive method of the first object:
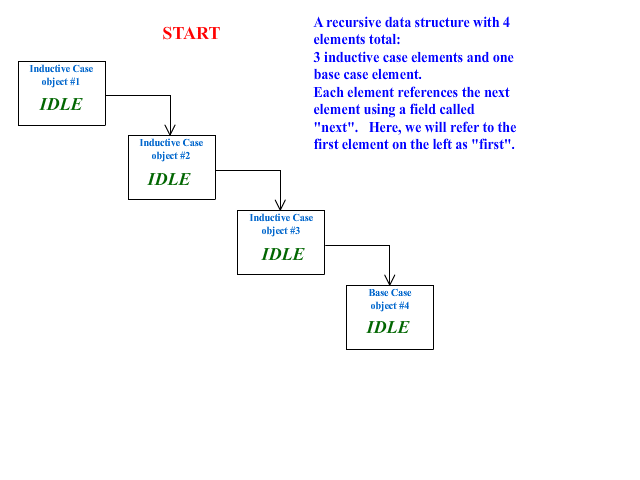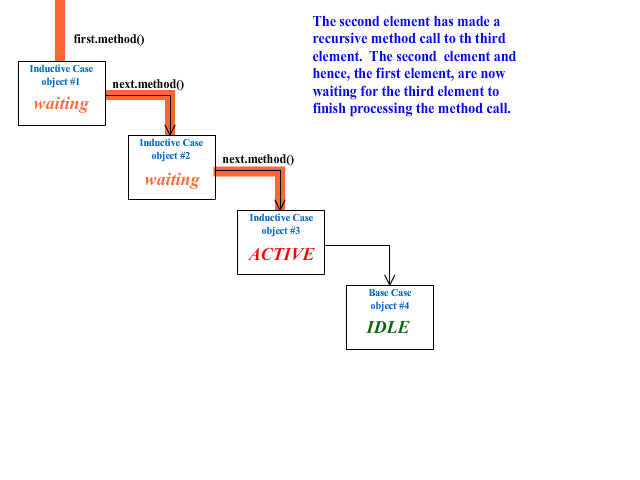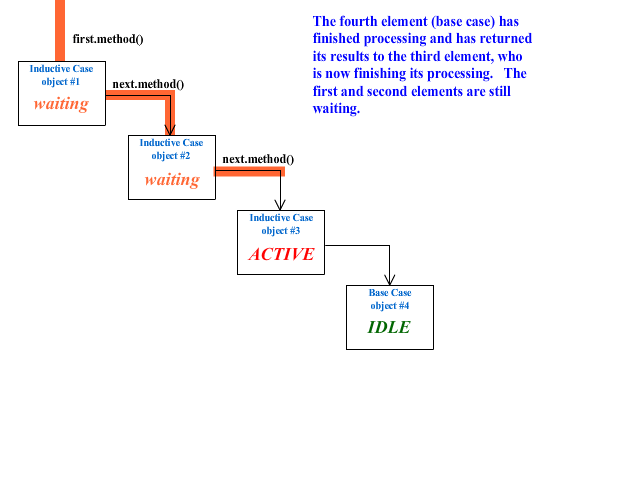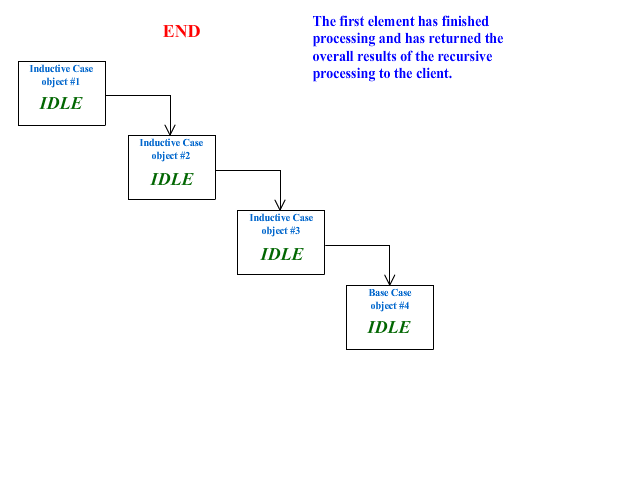
Tail Recursion
Consider the problem of finding the last element in a list. Again we need to interpret what it means to be the last element of (a) the empty list and (b) a non-empty list.
- Last element of the empty list: the empty list has no element; so there is no such thing as the last element for the empty list. How do we represent the non-existence of an object? For now, we use a key word in Java called null. null is a special value in Java that can be assigned to any variable of Object type to signify that the variable is not referencing any Object at all.
- Last element of a non-empty list with first and rest: it all depends on rest! rest has the capability to tell whether or not first is the last element of the current list. When rest is empty, then first is the last element. When rest is not empty, the first is certainly not the last element. rest has its own fist in this case, and it's up to the rest of rest to determine whether or not this new first is the last element! It's recursion again, isn't it?
To recapitulate, here is how a list can find its own last element.
- empty list case: return null or throw an exception to signify there is no such element.
- non-empty list case: pass first to rest and ask rest for help to find the last element.
How does rest use the first element of the enclosing list to help find the last element of the enclosing list?
- empty list case: the first element of the enclosing list is the last element.
- non-empty list case: recur! Pass its own first to its rest to help find the last element.
Here is the code.
/**
* Represents empty lists.
*/
public class MTList implements IList {
// Singleton Pattern
public static final MTList Singleton = new MTList();
private MTList() {
}
/**
* Returns null to signify there is
* no last element in the empty list.
*/
public Object getLast() {
return null;
}
/**
* Returns acc, because being the
* first element of the preceding
* list, it is the last element.
*/
public Object getLastHelp(Object acc) {
return acc;
}
}
|
/**
* Represents the abstract list structure.
*/
public interface IList {
/**
* Returns the last element in this IList.
*/
Object getLast();
/**
* Given the first of the preceding list, returns the last element of the preceding list.
* @param acc the first of the preceding list.
*/
Object getLastHelp(Object acc);
}
|
/**
* Represents non-empty lists.
*/
public class NEList implements IList {
private Object _first;
private IList _rest;
public NEList(Object f, IList r) {
_first = f;
_rest = r;
}
/**
* Passes first to rest and asks for
* help to find the last element.
*/
public Object getLast() {
return _rest.getLastHelp(_first);
}
/**
* Passes first to rest and asks for
* help to find the last element.
*/
public Object getLastHelp(Object acc) {
return _rest.getLastHelp(_first);
}
}
|
The above algorithm to compute the last element of a list is another example of forward accumulation. Note that in the above, getLast is not recursive while getLastHelp is recursive. Also note that for the NEList, the last computation in getLastHelp is a recursive call to getLastHelp on _rest. There is no other computation after the recursive call returns. This kind of recursion is called tail recursion. Tail recursion is important for program performance. A smart compiler can recognize tail recursion and generate code that speeds up the computation by bypassing unnecessary setup code each time a recursive call is made.
.