COMP 310
|
Lec19: Visitors... |
|
|
Let's continue our discussion of visitors from last lecture.
Important points to remember:
Here is a nice write-up about the visitor pattern by a former Comp310 student, Nav Ravindranath (Fall 2014), who rediscovered the visitor pattern when he got to industry: http://blog.delphix.com/nav-ravindranath/2016/04/27/accepting-the-visitors/ Note how coming to understand design is an iterative process of continually re-evaluating one's own work and thoughts.
Consider the following Visitor Design Pattern implementation:
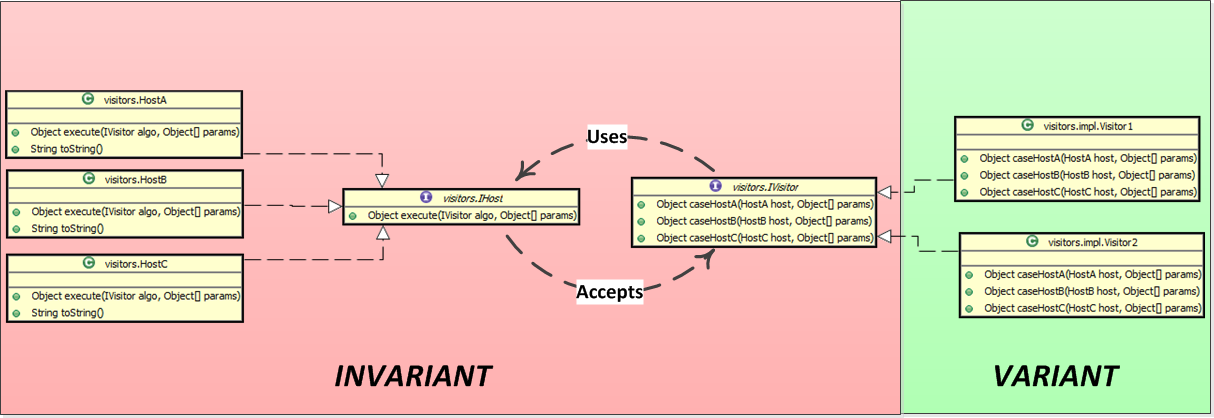
Also, see the List Framework (listFW) visitor demo.
A host calls its corresponding case on the visitor -- That's the only thing the host knows how to do. It's case is the only case it is aware of. In some sense, this behavior defines the host.
A host executes a visitors without semantic -- the host has no idea what a visitor does.
A visitor simply provides the services of its cases -- A visitor does not know when or how it will be used.
Hosts provide intrinsic, atomic behaviors for the visitors to use -- The hosts must provide the host-dependent behaviors that cannot be done by anyone else.
Visitors create algorithms by combining the atomic, intrinsic behaviors of their hosts -- Visitors are fundamentally external to the hosts and thus visitor behavior can only be based on the public methods offered by the hosts.
The hosts and the visitor are mutually dependent on each other -- a host needs a visitor to execute its algorithms and a visitor needs a host to provide its intrinsic behaviors.
The number of hosts is invariant -- The number of host classes is tied to the number of cases the visitor provides because there is a one-to-one relationship between the two. This is a critical design decision.
The number of visitors is variant - A finite number of hosts can support an arbitrary number of visitors.
Visitors do NOT depend on the inter-relations between hosts -- It is a common myth that visitors are tied to recursion and composite data structures. Visitors are usable on any abstract host hiearchy where distinguishable hosts are identifiable.
To run a visitor-based processing of a host, neither the visitor nor the host concrete types needs to be known -- The visitor system runs at the top interface levels so it decouples from the specifics of which type of host is currently present and which type of visitor is currently being used. Arbitrary processing of arbitrary data.
Visitors are the most effective in situations where multiple or changeable algorithms (processing) need to be run on objects at a point in the system where the type of the objects is not known but yet the algorithm depends on the object's type.
This is a surprisingly common situation in highly abstract systems.
FoldRAlgo and as an accumulator with
FoldLAlgo:Integer.MIN_VALUE
is the smallest possible Java integer value) FoldLAlgo:You are absolutely encouraged to attempt more algorithms! The more practice you get in writing visitor algorithms, the better off you will be for the rest of the semester!
Always remember these tips to help prevent common mistakes when working with visitors!
HostX.execute() --> return visitor.caseHostX(this,
params)result = host.execute(visitor, params)
host.getRest().execute(this, params)
caseX() methods
so they all have the same name but different overall
method signatures?If one looks around the web, one will often run across implementations of the
visitor pattern where instead of having case methods like this
where each method's name corresponds to its semantic,
public interface IVisitor {
public Object caseA(HostA host, Object... params);
public Object caseB(HostB host, Object... params);
public Object caseC(HostC host, Object... params);
}
the implementers instead override the case methods so that all the cases have the
same method
name and the compiler automatically distinguishes between the cases by the
invoked signature, i.e. by the host parameter's type:
public interface IVisitor {
public Object case(HostA host, Object... params);
public Object case(HostB host, Object... params);
public Object case(HostC host, Object... params);
}
In this situation, the code for each host's execute() method
looks like this:
Object execute(IVisitor visitor, Object... params) {
return visitor.case(this, params); // the type of "this" depends on the type of the host
}
This seems like a nice shortening of the code with perhaps the advantage of fewer typo errors by calling the wrong case by the wrong host because all the code looks the same and the proper dispatching is handled by the compiler.
This is a very common question, so it bears spending a little time in discussion.
Semantic clarity
It is true that technically, Java utilizes the entire method
signature, which includes not only the method name but the types of the
input parameters, to determine how to dispatch a call, that is to decide which
specific method to actually call in any given situation. Java thus
allows a developer to override a single method name with multiple
methods, so long as each overridden method has unique parameter types
and order. The above execute method's code will "work"
because the type of the host known to the compiler and thus the compiler can
figure out which of the overridden case methods to call when each
of the different host types calls the case method.
The problem is that the different case methods are fundamentally different in
semantics, that is, each case has the particular semantic of processing a
specific type of host. The semantics of the different
cases are NOT equivalent. But when one looks at the code
above, since the code is identical from one host to another, the
semantics of the call are not obvious from just reading the words of the code;
one has to take the additional step of realizing that the semantics of the call
are bound up in the type of the this parameter (the host).
On the other hand, the semantics of a call that is "return
visitor.caseA(this, params)" are patently obvious because we can see
right away that we are calling the case to process a type "A" host.
The purported time and error savings of overriding the case
methods is overstated because remember that the host code is on the
invariant side of the system. That means that while the hosts'
execute methods apear to be easier to write, this is only ever
happening once. The host code is written once and it is done
forever, so the time and error savings are minimal at best but at the cost of
semantic clarity.
For large systems, semantic clarity is paramount for insuring that the system behaves properly. For that reason, here we will always favor semantic clarity over code simplification.
Mutable hosts
The implict assumption that we have made in all of discussions so far is that the "type" of the host is immutable, that is, the apparent type of a host never changes. In fact, the visitor implementations that utilize case method name overriding rely on this invariant.
But if one closely examines the the requirements of the visitor design
pattern, we see that the only required invariant is that a "host call its
associated case". There is no statement that says that
the case called is the same case for all time, that is, the case a host calls is
time invariant. In fact, one way to define a "host" is to turn the
visitor pattern around and state, "HostX" is that
entity which calls the visitor's "caseX()" method.
Here, the visitor actually defines the host!
In fact, there are objects whose behavior changes in such ways that they literally appear to change type. This phenomenon is called "dynamic reclassification" is is modeled by the State Design Pattern. In these mutable data structures, any given host will call different cases on the visitor depending on what has happened to the host in the past. Examples of such data structures, including how they work with visitors, are mutable lists (Mutable Linear Recursive Structure) and the mutable binary tree (Binary Tree Structure). Unfortunately, a detailed discussion of dynamic reclassification is beyond the scope of this class -- see the beginning of COMP 405/505 .
Because the host's apparent type is mutable, the case methods cannot be typed to a specific host subtype (which doesn't even exist publicly), instead all cases must accept the top-level mutable host type:
public interface IVisitor {
public Object caseA(MutableHost host, Object... params);
public Object caseB(MutableHost host, Object... params);
public Object caseC(MutableHost host, Object... params);
}
In this situation, the technique of overriding the case methods with the same method name will NOT work at all because the cases are indistinguishable if the method names are identical. But by retaining case method names that are linked to their semantics, even "type-changing" hosts have no problem with always invoking the proper case on the visitor for the current "type" (state) of the host.
(Note: To insure that proper type-dependent processing of the host's current "type", algorithms for mutable data structures must always delegate to the host for any processing that might be type-dependent, i.e. everything is written as visitors. The hosts are built to always call the proper case on the visitor corresponding to their current "type"/state.)
Conclusion
While overriding case methods to all have the same name but different host type parameters will compile and execute just fine for immutable host data structures, the technique gives up semantic clarity for minimal developer advantages. Plus, when extending the notion of visitors to mutable data structures, that technique breaks down completely.
Favoring semantic clarity over convenience not only helps in clarifying, emphasizing and ensuring proper system behavior, overall extensibility and flexibility is enhanced because a system is defined by its semantics not by its code.
© 2017 by Stephen Wong