COMP 310
|
Lec26: RMI continued... |
|
|
Let's continue with our RMI discussion from last time...
Please reference the instructions for HW07 for this lecture.
The designers of RMI chose an unfortunate terminology to describe the various parts of the RMI system: "client" and "server". These terms often clash with the more colloquial usage of those terms to describe network architectures.
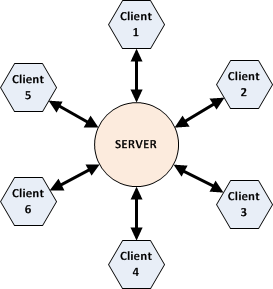
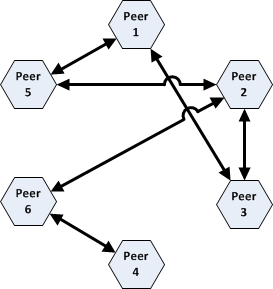
Colloquially, the "client" is the part of a networked program that many users are operating to request services from a single central "server". Thus a classic "client-server" architcture consists of multiple clients connecting to a single central server. This is in contrast to the classic "peer-to-peer" architecture, where there is no central server and each peer provides some of the services needed by the other peers, thus resulting in network connections that go from one peer to the next on an equal level.
| Client-Server Architecture | Peer-to-Peer Architecture |
 |
 |
On the other hand, the RMI system has very strict definitions for "client" and "server", which we will attempt to disambiguate by referring to as "RMI client" and "RMI Server":
RMI Client: The part of the program that requests an RMI stub from a Registry and uses that stub to perform remote services for it.
RMI Server: The object that from which an RMI stub is created an thus provides remote services for the RMI client via that stub. The stub is not the RMI server; the stub is just a proxy for the RMI server object.
In the Compute Engine project, we have several RMI client-server sets:
|
RMI Server object: |
RMI Client object that uses it: |
|
ComputeEngine |
ClientModel |
|
remoteTaskViewAdpt
|
ClientModel |
|
clientTVA |
ComputeEngine |
Bottom Line: RMI "clients" and "servers" do not always correspond to the colloquial usage of those terms!
RMI uses remote dynamic class loading to transparently transport the code for serialized objects from one machine to another when the target machine does not initially have the code for that object.
Remote dynamic class load process (all transparent to coder and user):
The tough part here is to get the java.rmi.server.codebase property set up correctly. See the supplied code to see how its done.
We will need to have a basic understanding of generics in order to complete the ComputeEngine project.
References:
In the ComputeEngine project you will notice some interestingly declared classes. Here are two examples:
/**
* A abstract task to be run on the computer engine
* @param <T> The type of the returned result of the task
*/
public interface ITask<T> {
/**
* Executes the task and returns a result
* @return The result of executing the task.
* @throws RemoteException thrown when a network error occurs.
*/
public T execute() throws RemoteException;
/**
* Sets the adapter to the view properly for this object.
* @param viewAdapter an adapter to the view.
*/
public void setTaskViewAdapter(ILocalTaskViewAdapter viewAdapter);
}
and
/**
* Generalized lambda that takes a vararg of input parameters and has no return value.
* @author swong
*
* @param <P> The Type of the input parameters
*/
public interface IVoidLambda<P> {
/**
* Run (apply) the lambda
* @param params vararg of input parameters
*/
public void apply(P...params);
}
The funny letters in the angle brackets, "T" and "P" above are called "generic types". The above code is a way of writing classes such that they will work for a variety of types, not just some explicitly coded ones.
For instance, in the ITask declaration, the "T" means that whatever we specify for "T" when the class is used is the return type for the execute method. For instance I can use the above task interface definition to write:
ITask<String> myTask = new ITask<String>() {
public String execute() {
// yadda yadda
}
//etc
}
IVoidLambda<Integer> myLambda = new IVoidLambda<Integer>() {
public void apply(Integer... params) {
// yadda yadda
}
};
The beauty here is that myTask is strictly defined now to the compiler to return a String from its execute method. Likewise, myLambda is strictly defined with an apply method that takes Integers as its vararg. If I write something that violates that, the compiler will catch it and warn me.
String s = myTask.execute(); //OK
ITask<String> anotherRef = myTask; // OK
myLambda.apply(3, 10, 42); // OK
All of the following will generate a compile error due to type-safety violations:
Double x = myTask.execute(); // ERROR! Wrong return type.
IVoidLambda<String> myOtherLambda = myLambda; // ERROR! myLambda is defined as IVoidLambda<Integer>
myLambda.apply("hello world"); // ERROR! Wrong input type.
ITask<String> myTask = new ITask<String>() {
public Double execute() { // ERROR! Incorrect return type being declared.
// yadda yadda
}
//etc
}
The above examples all impose the generic type definitions at a class-level. That is, the type parameter (e.g. "T" or "P" above) apply to everything that is in the class and are invariant once a subclass or implementation has been defined for a specific value of that type parameter. That's what generated the type safety in the examples above.
However, it is possible to declare generic types at the method-level, where it is dynamically applied (not really, actually, but we can think of it as such for our purposes here). Take a look at the executeTask method of ComputeEngine:
public <T> T executeTask(ITask<T> t) {
// non-relevant code elided
T result = t.execute();
return result;
}
The intepretation of this code is that "<T>" defines a type "T" that must be self-consistent for any call to executeTask. That is, if T is String, then the input parameter must be of type ITask<String> and the return type will be a String.
But Java does this one better: the type T is inferred from the types involved in the call to executeTask. So the argument really goes like such:
"If executeTask is called with an input parameter of type ITask<String>, the return type is String."
Thus the input type determines the output type.
This argument is applied on a per-call basis, that is the type T may change between different calls. Thus the following code snippet is perfectly valid:
ITask<String> stringTask = someAppropriateValue; ITask<Integer> intTask = someOtherAppropriateValue; int i = myComputeEngine.executeTask(intTask); // returns Integer because intTask is defined with Integer type. String s = myComputeEngine.execute(stringTask); // returns String because stringTaskis defined with String type.
The following is illegal however:
double x = myComputeEngine.executeTask(stringTask); //ERROR! Using stringTask forces the output to be a String, not double.
Method-level generics enable us to use different input types that result in different return types but to be able do so with full type safety.
Something to think about: How do you think that generics could be used to solve the problem of always having to cast the "Object" type return of visitors?
Generics give us flexibility and type safefty!
© 2018 by Stephen Wong