Lab 6 - Advanced Linked Lists
Lab goals:
- Understand the importance of dynamically resizing a hash table.
- Practice the implementation and usage of circular doubly-linked lists.
- Make use of the hash table to aid in maintaining word usage counts in the spell checking program.
More on Resizing Hash Tables
As described in last week's lab, hash tables are often dynamically resized as the occupancy of the hash table increases, to reduce the length of the collision chains. Smaller collision chains enable faster lookups and removals.
For example, below we illustrate the impact of resizing
hash tables in the spell checking program from last week's
lab. The figures below show the hash table structure after
all 479828 words from /usr/share/dict/words
have been inserted into the hash table, with and without
table resizing.
Without Resizing
When hash table resizing is not enabled, the size of the
hash table remains at its initial array size of 2, and
loading all of the 479,828 words from the dictionary
/usr/share/dict/words results in two
huge collision chains with 239,761 and 240,067
elements, respectively. Traversing these linked lists to
perform lookups and removals would be very
slow:

With Resizing
When hash table resizing is enabled, the hash table's array size grows from 2 entries to 524,288 entries as the words are inserted. After all of the 479,828 words have been inserted into the hash table, the average length of the collision chains is only 0.9152 (for the load factor threshold of 1.5). This enables very fast hash table lookups and removals:

Keeping Counts of Dictionary Word Usage
Our goal here is to enhance the spell checking program to also maintain the usage counts of the words in the dictionary as it spell checks the input documents. Moreover, we want the program to order the dictionary words in this counting by their usage counts and to then print the dictionary words ordered by usage counts after all input documents have been checked.
To simplify the task, we will maintain the order only
for usage count values of up to MAX_COUNT - 1
(i.e., only for words each used up to that many times).
Usage count values greater than or equal to
MAX_COUNT will not be ordered with respect to
each other and will instead all be treated equally, as if
their count were each just equal to
MAX_COUNT.
The implementation of word counting in
spell_check.c uses a circular doubly-linked
list to record all words from the dictionary that have
the same usage count (so far) in the execution of the spell
check. The header of each of these lists is referred to as
a dummy
header since it is of the same format as
each of the real
list entries but does not actually
define any data in the list; its role is just to serve as
the header of that list. Each one of these circular
doubly-linked lists used for keeping track of the
dictionary word usage counts thus looks like this:
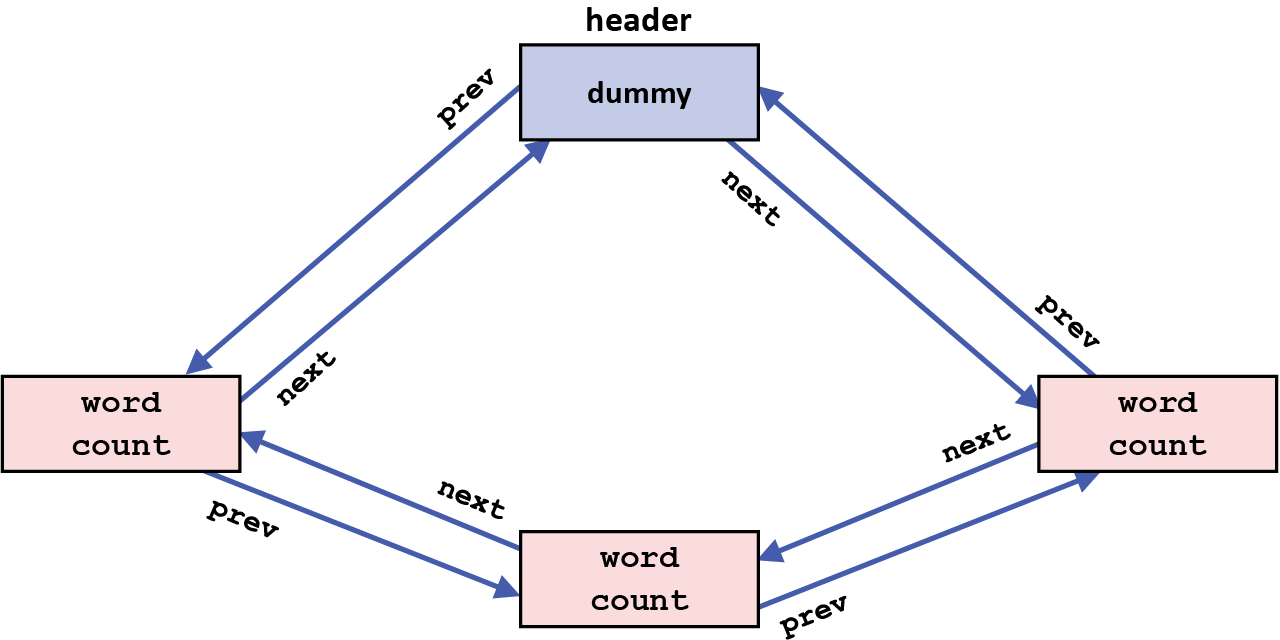
The implementation in spell_check.c uses an
array of these dummy
list headers, each
serving as the header of a separate circular doubly-linked
list. The number of entries in this array of
headers is MAX_COUNT + 1.
Each of these circular doubly-linked lists (headed by
one of the entries in this array) corresponds to a word
usage count value that is equal to the array index value
for that header. That is, all words with a usage count
value of x are recorded within the circular
doubly-linked list whose header is at entry x in
the array. However, all words whose usage count is
greater than MAX_COUNT are all
also stored in the circular doubly-linked list
whose header is at entry MAX_COUNT in the
array, together with all words whose usage count is
equal to MAX_COUNT.
The resulting usage counting data structure looks like this:

The benefit of using circular doubly-linked lists like this is that any entry in the list, given just a pointer to that entry, can be removed from the list in constant time; and given just a pointer to any entry in such a list that we want to insert some new node after, the new node can be inserted in constant time. Thus, in maintaining the usage count data, when the usage count of a word increases, the word can be removed in constant time from the circular doubly-linked list corresponding to the word's old usage count, and can then be inserted, also in constant time, into the list corresponding to the word's new usage count.
The code below, from today's lab, shows the definition
of the structure used for maintaining the word usage count
data and the procedure used for initializing the array
maintaining these counts (notice how the next
and prev fields are initialized in each list
header):
/*
* A doubly linked list node structure for maintaining word
* usage count statistics.
*/
struct word_data {
const char *word;
unsigned int count;
struct word_data *next;
struct word_data *prev;
};
/*
* Requires:
* Nothing.
*
* Effects:
* Allocates and initializes an array of struct word_data,
* with each entry representing the dummy head of a circular
* doubly linked list. Each list stores words with a particular usage
* count value equals to the array index value. Words with usage count
* greater than or equal to MAX_COUNT are all stored in the list at the
* array index MAX_COUNT.
*/
struct word_data *
init_word_count_array(void)
{
struct word_data *wda;
int i;
wda = malloc(sizeof(struct word_data) * (MAX_COUNT + 1));
if (wda == NULL)
return (NULL);
for (i = 0; i <= MAX_COUNT; i++) {
wda[i].word = NULL;
wda[i].count = i;
wda[i].next = &wda[i];
wda[i].prev = &wda[i];
}
return (wda);
}
The word member in the struct points to the dictionary word for this element in the list, and the count member records the number of times that word has been used during the spell check. In the list header, the count value should be the same as for any words in that list (all words with the same usage count are on the same list), but the word pointer in the header should be NULL since the header does not define the usage count for any actual word.
Circular Doubly-Linked List Element Insertion
As described above, a circular doubly-linked list is a data structure that enables you to remove any item in the list or to insert a new item anywhere (after any given existing item) in the list in constant time.
The figures below illustrate the sequence of steps
involved when inserting a new element after some existing
element in a circular doubly-linked list; the existing
element being inserted after here is the dummy
header element, and thus this new element is being inserted
at the beginning of the list. The new element being
inserted, as well as the two existing pointers that will
need to be changed for this insertion, are shown below in
red:
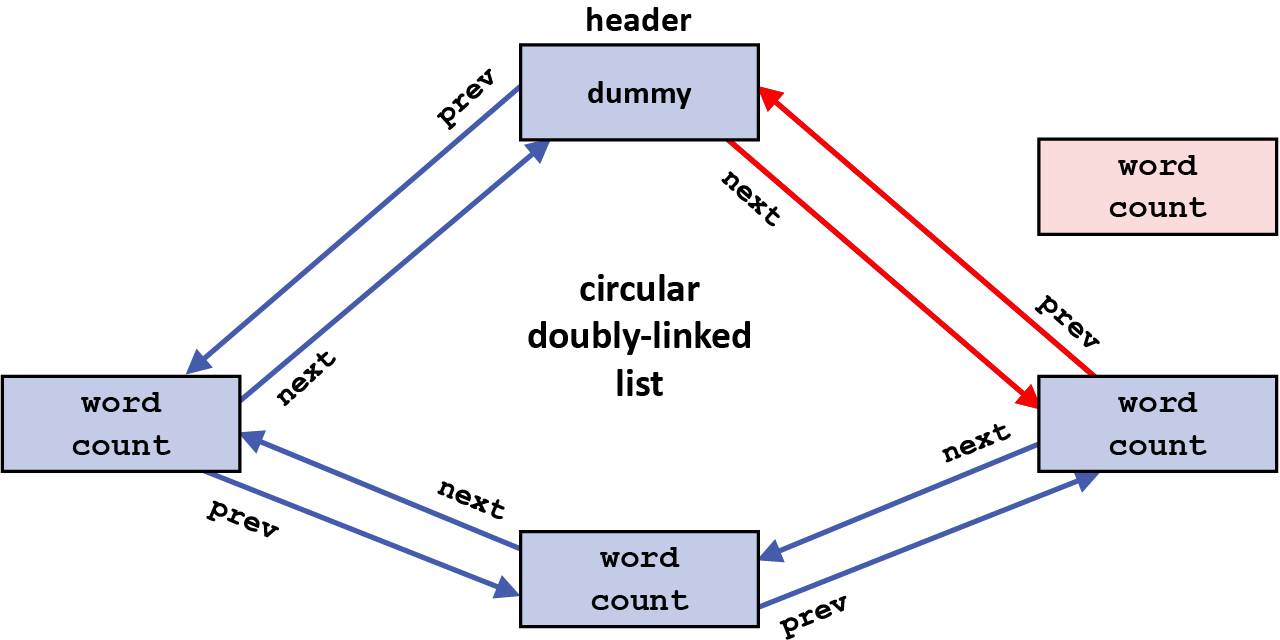
The first step in inserting the new element is to use the next pointer in the element being inserted after (here, the header element) to find the element being inserted before (the element that follows the one being inserted after); the prev pointer in that element is changed to point to the new element being inserted (the grayed-out arrow shows the original value of that prev pointer):
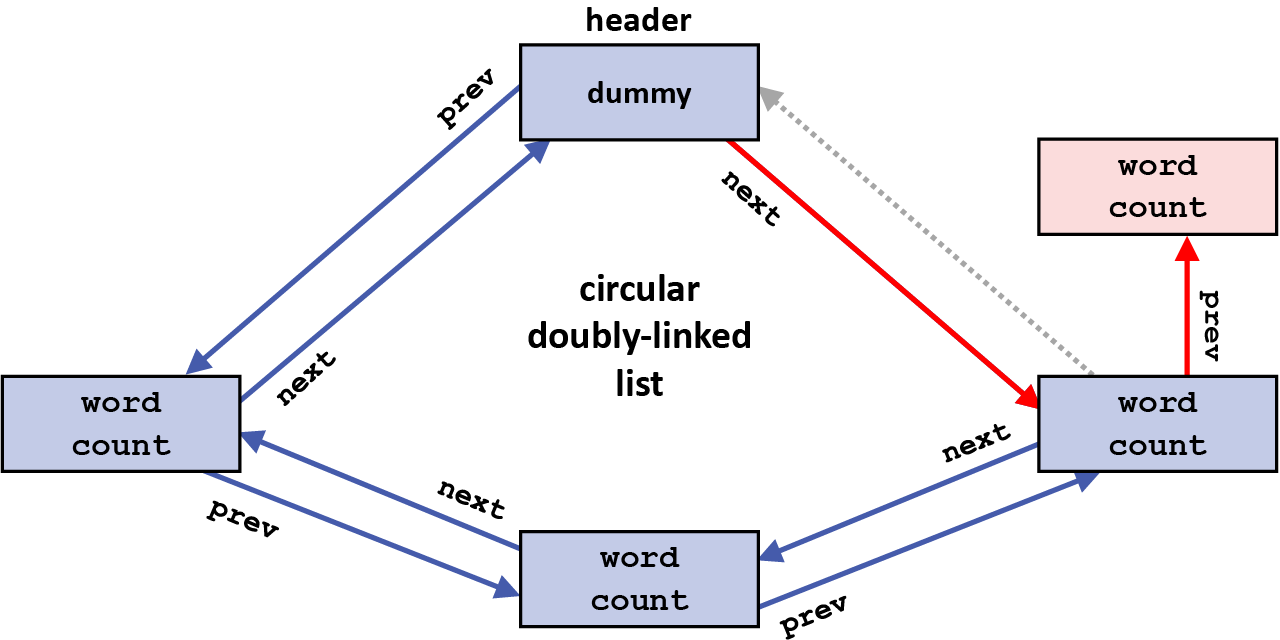
And then, the next pointer in the element being inserted is changed to point to that same element, which will now follow the new element after the insertion:
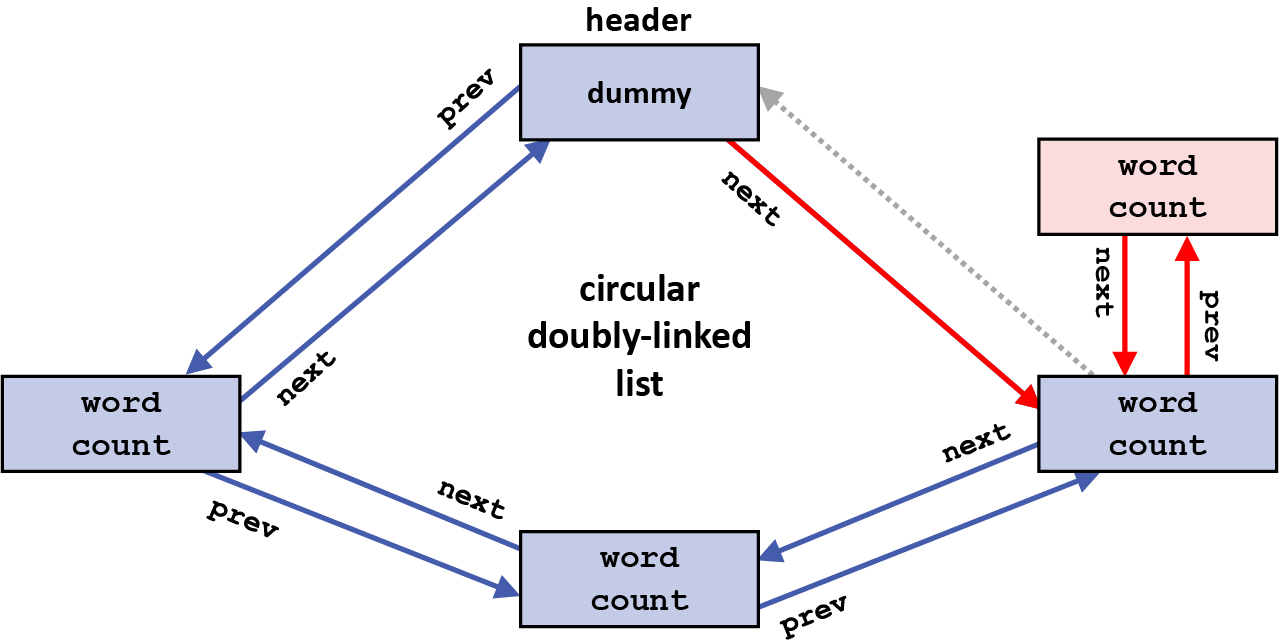
Now, the prev pointer in the element being inserted is changed to point to the element it is being inserted after (here, the header element), since it will precede the new element after the insertion:
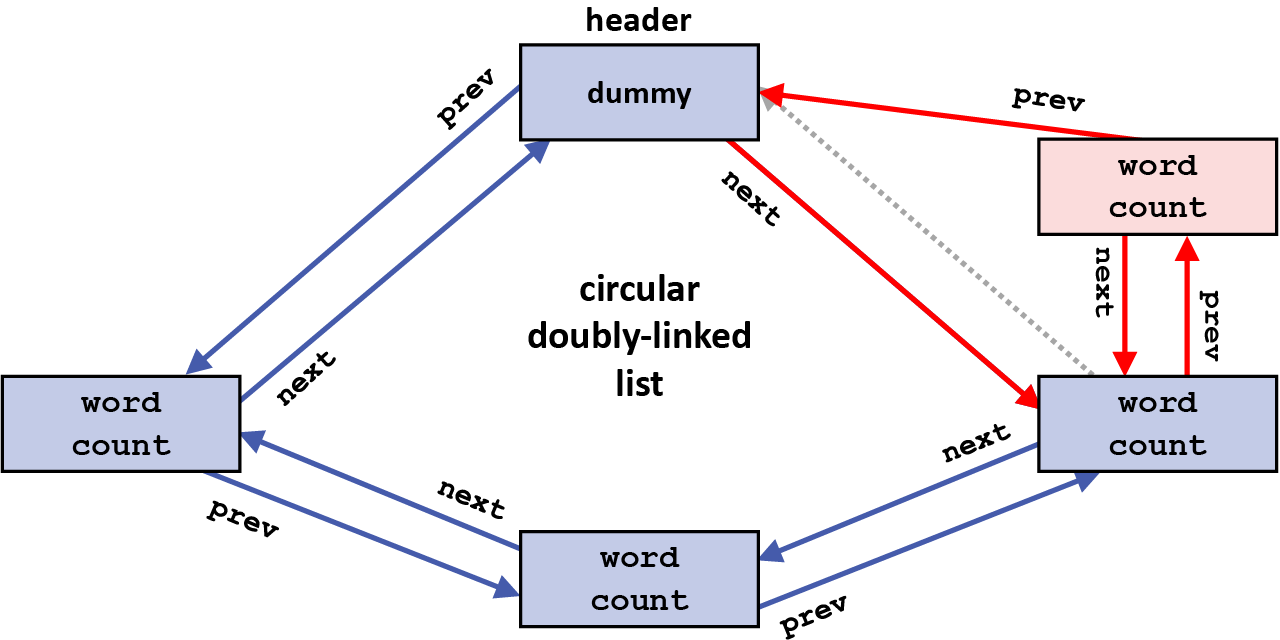
And finally, the next pointer in the element being inserted after (here, the header element) is changed to point to the element being inserted (the new grayed-out arrow shows the original value of that next pointer):

This completes the insertion of this new element into the circular doubly-linked list.
Some of the advantages of using a circular doubly-linked list as a list data structure have already been mentioned. But to summarize them all here, perhaps the two most important points are, first, that all insert (and remove) operations can be done in constant time, regardless of where in the list the operation is taking place; and second, that there are no special cases needed in handling any such operations, including if the list is empty before the insert (inserting the first item into an empty list). Just follow the same sequence of pointer operations and changes; and treat the list header just the same as any other element in the list.
In particular, for inserting into a circular doubly-linked list, above we showed inserting after the header into a non-empty list. But inserting after any existing element, or inserting into an empty list (as the new first element in the list), works exactly the same way. And inserting before any given element (into an empty or non-empty list) is just as easy In all cases, for inserting into a circular doubly-linked list, you only need the address of the element to insert after or before (there are no special cases).
Circular Doubly-Linked List Element Removal
The figures below illustrate the sequence of steps involved when removing an element from a circular doubly-linked list. The element being removed, as well as the two pointers that will remain part of the list that will need to be changed for this removal, are shown below in red:
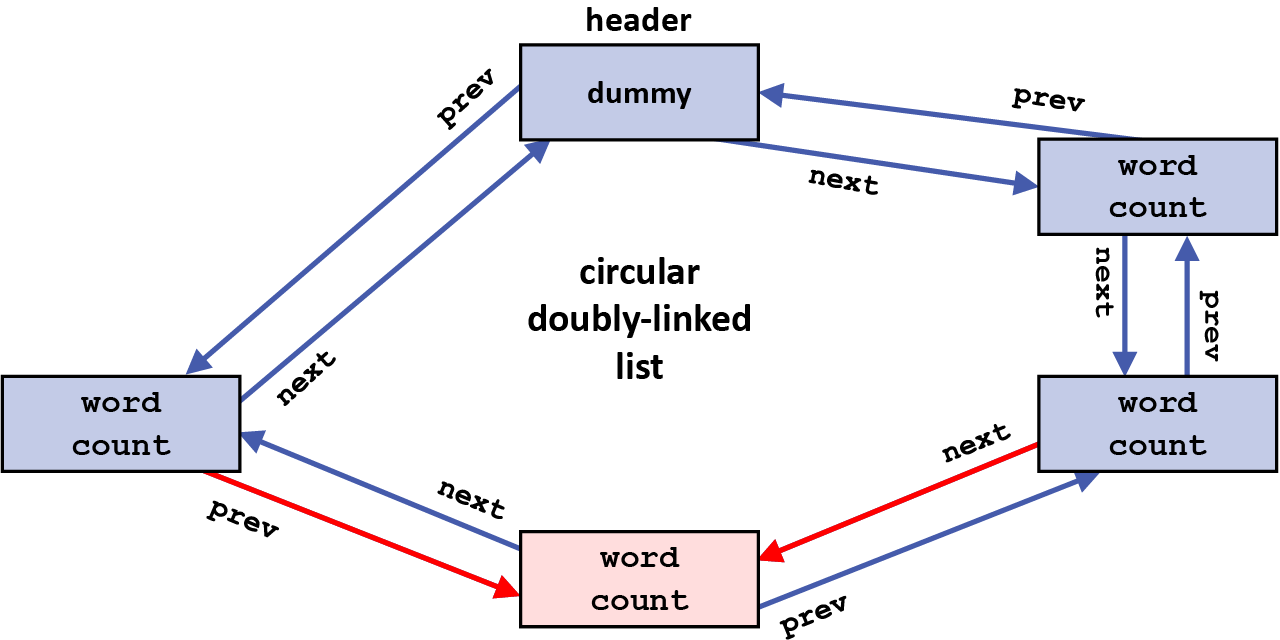
First, the prev pointer in the element being removed is used to find the preceding element in the list, and its next pointer is changed to now point to the same element as the next pointer of the element being removed now points to. In effect, the next pointer of the preceding element now bypasses the element being removed, since that element will not be part of the list once the removal is complete (the grayed-out arrow shows the original value of that next pointer):

Then, essentially the same thing happens, but in the other direction. The next pointer in the element being removed is used to find the following element in the list, and its prev pointer is changed to now point to the same element as the prev pointer of the element being removed now points to. In effect, the prev pointer of the following element now bypasses the element being removed, since that element will not be part of the list once the removal is complete (the new grayed-out arrow shows the original value of that prev pointer):
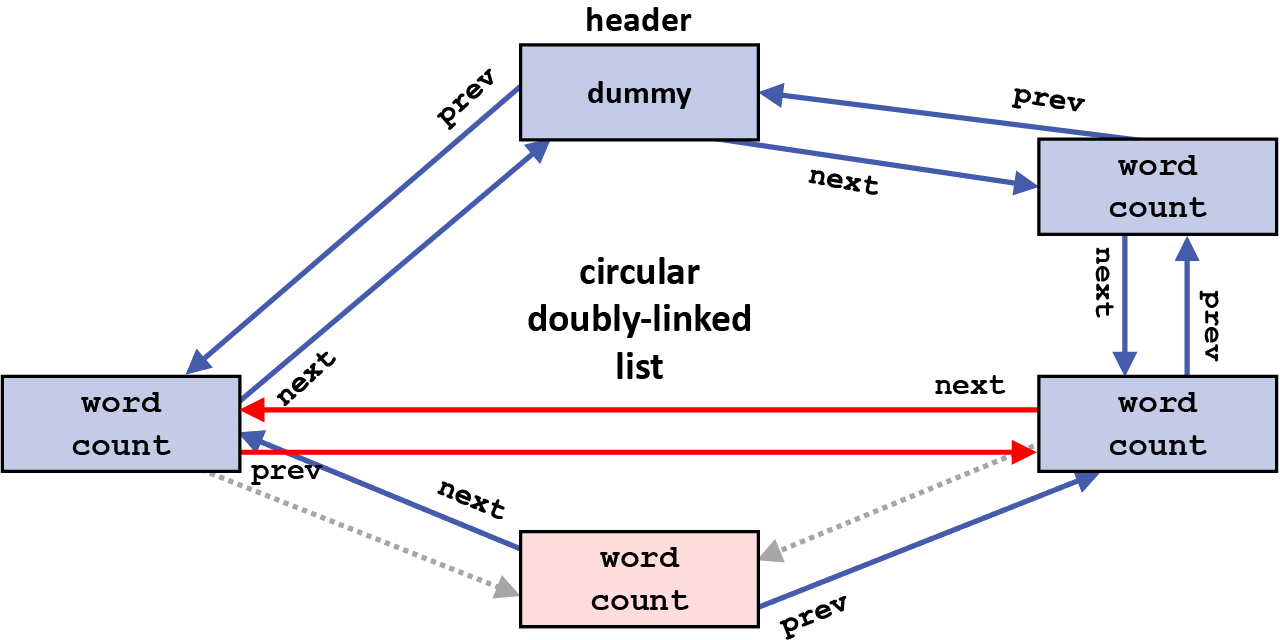
This completes the removal of this element from the circular doubly-linked list. The figure below also shows the next and prev pointers as grayed out in the element that has been removed, since those pointers are also no longer part of the list now that this element has been removed from the list (the value of these two pointers are no longer relevant to the list):
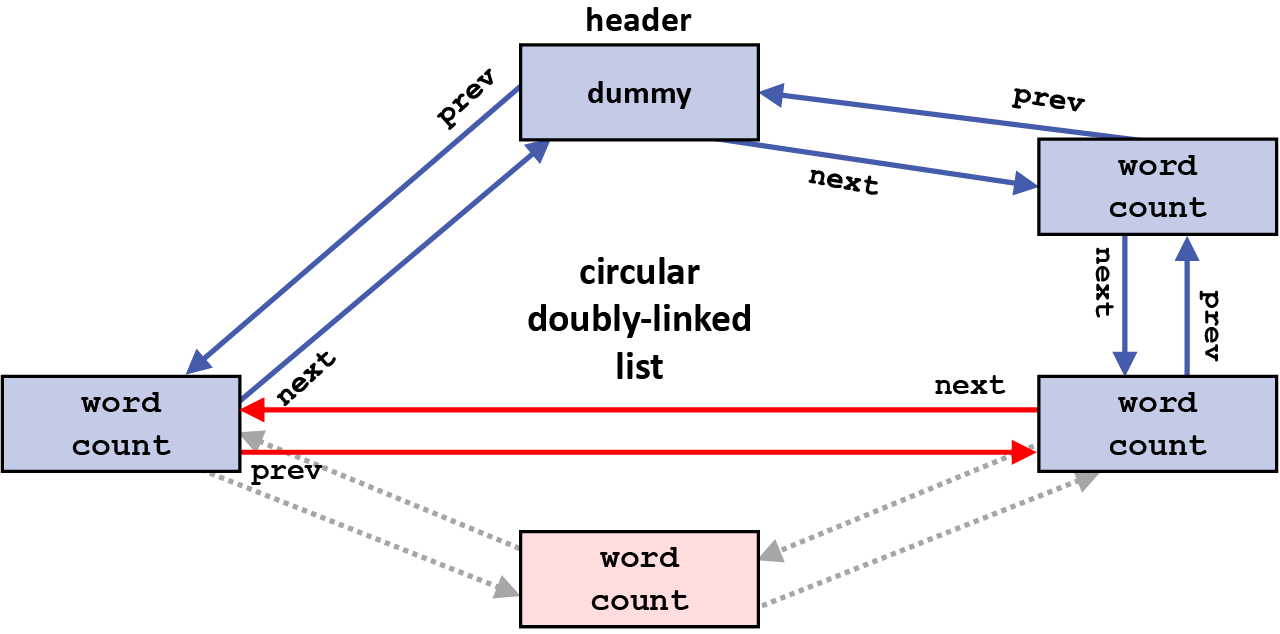
As with the discussion above for insert operations, the same basic advantages hold for remove operations. In summarizing here these advantages of using a circular doubly-linked list, perhaps the two most important points are, first, that all remove (and insert) operations can be done in constant time, regardless of where in the list the operation is taking place; and second, that there are no special cases needed in handling any such operations, including if the list will be empty after the remove (removing the last item and leaving the list empty). Just follow the same sequence of pointer operations and changes; and treat the list header just the same as any other element in the list.
In particular, for removing from a circular doubly-linked list, above we showed removing one element, leaving the list non-empty. But removing one element, leaving the list empty (in other words, removing the last element from the list), works exactly the same way. In either case, you never need to traverse the list as part of the remove. Completing the remove operation can always be performed in constant time. In all cases, for removing from a circular doubly-linked list, you only need the address of the element to remove (there are no special cases).
Writing the Dictionary Word Usage Count Statistics to an Output File
In this week's spell check program
spell_check, we have added a new command line
option -o
output_file_name. The purpose of this option
is to request writing to the specified output file each
word in the dictionary together with its usage count. This
output is implemented by passing the address of the
output_word_data() function to
hash_table_iterate(), and passing as the
cookie the FILE * stream pointer
for the opened, writable output file stream.
NOTE that using hash_table_iterate() will not print the words in sorted order.
GitHub Repository for This Lab
To obtain your private repo for this lab, please point your browser to this link for the starter code for the lab. Follow the same steps as for previous labs and assignments to to create your repository on GitHub and to then clone it onto CLEAR. The directory for your repository for this lab will be
lab-6-advanced-linked-lists-name
where name is your GitHub userid.
Submission
Be sure to git push the appropriate C source files for this lab before 11:55 PM tonight, to get credit for this lab.