Lab 8 - Implicit Free List Memory Allocator
Lab goals:
- Become familiar with a memory allocator that is based on an implicit free list.
- Make two simple changes to the memory allocator source code.
Lab Overview
In the repository for this week's lab, you will find
source code that implements a memory allocator (like the
malloc function) that is based on
first-fit allocation, using an implicit free
list with boundary tag coalescing. Do not
worry now if you do not know exactly what this description
means. By the end of this week's lectures, you should have
a much better idea.
In the repository, you will also find source code for a program named mdriver for testing the memory allocator, a Makefile, and some test files. To see things work, do this:
make ./mdriver
The mdriver program executes a series of allocate, reallocate, and free operations and can be used to test your memory allocator and its performance. You should see output from mdriver that includes a line of measurements like this (your numbers may not exactly match these):
Perf index = 31/40 (util) + 60/60 (thru) = 91/100
Your next programming assignment will be to
program a memory allocator of your own. You will pick the
algorithms for your allocator. The lectures on Dynamic
Memory Allocation
explain more about metrics for memory
allocation such as those reported by mdriver. In
addition, next week's lab and the specification for your
next programming assignment will contain more details on
these mdriver measurements.
For this week's lab, we will focus on the correct operation of your memory allocator and not (for this lab) on its performance. You do not actually need detailed knowledge of memory allocation for this lab.
However, note that the memory allocator given in your repository for this week's lab returns blocks of memory that are aligned on 16-byte boundaries. In this lab, you will modify it to instead align just on 8-byte boundaries.
To help you accomplish this task, we will walk through the code below. The work you do in this lab will help you implement your next programming assignment.
Source Code Walkthrough
The starting source code for the memory allocator is available in your repository in the file mm.c. Below we will walk through some features of how this code works.
Overall Structure of the Heap
The heap using this memory allocator is represented as a
list of blocks, including all free blocks as well
as all allocated blocks of memory. Each block
begins with a header and ends with a
footer, both of which give the total size
and the status (0 for free vs. 1 for
allocated) of the block. The entire heap begins
with one prologue block (including a prologue
block header and footer) and finally ends with one
epilogue block header (the epilogue block has no
footer). The figure below depicts the overall structure of
the heap (here showing a heap consisting of n
blocks, with hdr
marking each allocated or free
block header and ftr
marking each allocated or free
block footer):
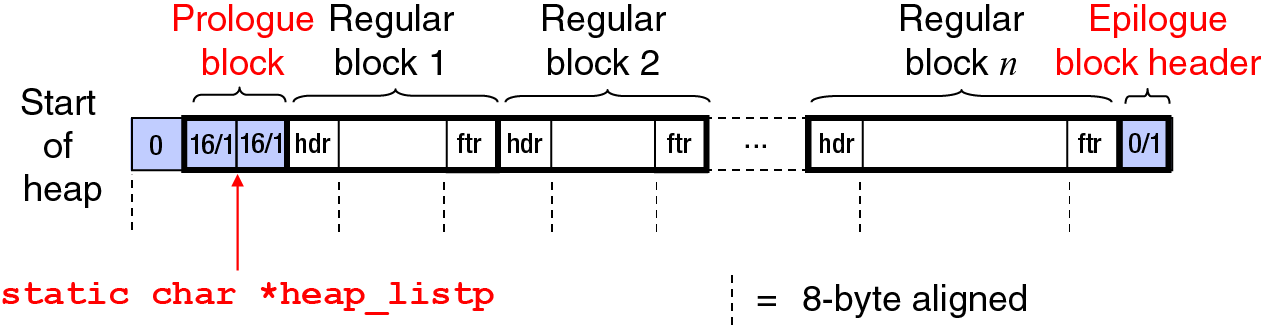
The global variable heap_listp within mm.c defines the location of the heap by pointing into the prologue block at the beginning of the heap. The format of a prologue block is identical to regular blocks in the list, except that it consists only of its corresponding header and footer. For every other block, there are a non-zero number of bytes of data between the block's own header and footer, but for the prologue block, there is nothing between the header and footer. The pointer heap_listp points to where those (nonexistent) bytes are logically located within the prologue, and thus it actually points to the beginning of the prologue's footer, which would follow those (zero) bytes of data.
Within mm.c, the constant WSIZE
defines the size of a word
as well as the size of
each header and a footer in the list. The constant
DSIZE is twice (or double, as in D
) the
word size WSIZE. In this code, as compiled on
CLEAR, the value of WSIZE is 8 bytes, and
the value of DSIZE is 16 bytes.
In the figure above, the notation 16/1
in the
prologue block's header and footer gives the size (16
bytes) and status (1, meaning allocated) of the prologue
block itself. The size given for any block (including,
here, for the prologue block) includes the size of
the block's header and footer, as well as the size of the
block's data.
Similarly, the notation 0/1
in the epilogue block
header gives (what appears to be) the size (0 bytes) and
status (1, meaning allocated) of the epilogue block.
But there actually is no epilogue block. There is
only an epilogue block header. The important thing
is that this size of 0 occurs only in this
epilogue block header, since normally (even for the
prologue block) the size includes the size of the
block's header and footer and thus cannot be 0. As a
special case, to clearly mark the end of the list, the
epilogue block header has its size represented as 0,
and there is thus then no need to create and store a footer
to go with this epilogue block header.
The memory within all blocks (following the block's header) always begins and ends on an address that is aligned on an 8-byte boundary. The entire heap itself also always begins on an address that is aligned on an 8-byte boundary.
Initializing the Memory Manager
The memory manager is initialized by the function mm_init(). This function allocates the memory needed to store the prologue block (just a header and a footer) and the epilogue block header (again, there is no epilogue block footer). The figure below shows the format of this initial heap:
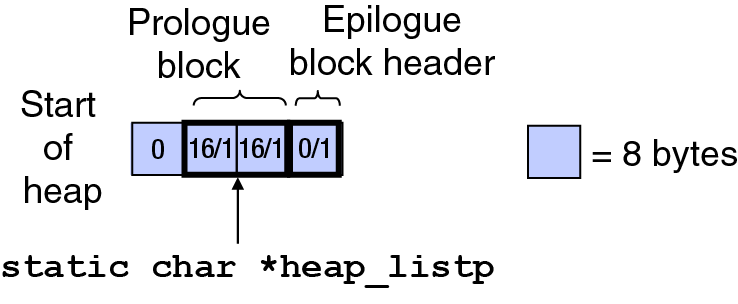
Each rectangle in the figure above is of size 8 bytes (which is WSIZE). The format of this initial heap is as described above, with no blocks in the list between the prologue block and the epilogue block header.
Within the code in mm.c, including in the function mm_init(), a number of C preprocessor macros are used to simplify operations on the format of the heap:
- PACK(size,
alloc) creates a
word
(WSIZE) to represent a header or footer with a size (again, including the header and footer) of size number of bytes, with an allocation status of alloc, with 1 meaning allocated and 0 meaning free. Since, due to alignment, the size will always be an even number (thus with its least significant bit always being a 0), the code actually uses this bit to instead store the allocation status of the block. - PUT(p,
val) puts a
word
val into the heap in memory at address p. - GET(p) reads from
memory and returns a
word
from address p.
Finally, mm_init() calls the function extend_heap() to allocate actual usable memory for the heap to be used in satisfying future memory allocations (the initial heap, as described above, contains only the prologue block and epilogue header). The size of this allocation is CHUNKSIZE number of bytes and is used in the same way each time the memory allocator needs to enlarge the total size of the heap. The function extend_heap() is described next below.
Extending the Size of the Heap
The total memory size of the heap is extended by the function extend_heap(). This function allocates CHUNKSIZE number of bytes and adds it to the list for the heap in the correct format. The figure below shows the format of this initial heap:
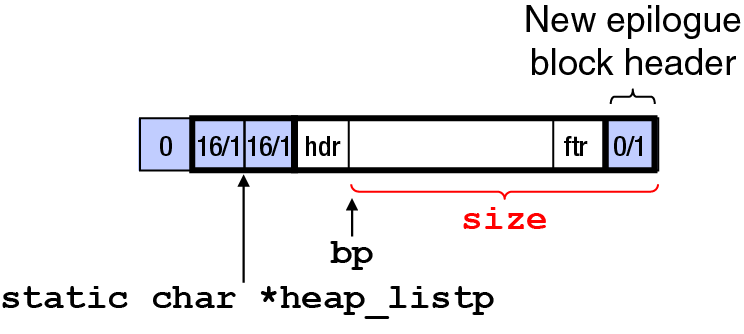
The argument to extend_heap() is
words, the number of words
to extend the
size of the heap by, but this number is translated into
size bytes by multiplying words by
WSIZE and and rounding that number up to a be a
multiple of WSIZE.
The extend_heap() procedure then uses
mem_sbrk() to allocate size number of
new bytes for the heap, with bp now pointing to
the beginning of this newly allocated space (the value
returned by mem_sbrk()). The code then formats
the new memory as a single free block in the memory
allocator's list, by using PUT to create the new
block's header and footer and create a new epilogue header.
Note that the old epilogue header gets reused to form the
new block's header and a new epilogue header is created at
the end of the newly allocated bytes. Finally,
extend_heap() effectively frees
this new
memory into the heap, calling coalesce
to
coalesce
this new block with the existing last block
of the heap.
Coalescing Free Blocks
The function coalesce() is used by the memory
allocator to coalesce
a newly freed block into the
heap. Specifically, coalesce examines the
allocation status (free vs. allocated) of the block before
the block being freed (shown here below that block) and the
block after the block being freed (shown here above that
block). Based on which or both (or neither) of these
adjacent blocks are also free, coalesce()
determines whether or not to combine this newly freed block
with these other blocks, depending on which of the
following 4 cases exist for this operation:

The allocation status of the newly freed block has
already been changed to free
before calling
coalesce(). If the preceding block is also free,
the effect is to combine this newly freed block with the
preceding block, creating a single, larger free block. And
if the following block is free, the effect is to combine
this newly freed block with the following block, creating a
single, larger free block. The code in
coalesce() does all of the necessary combining
at once, using the appropriate set of operations, depending
on which of these 4 cases it finds exists.
To do this, the code in coalesce() (and elsewhere in mm.c) uses several additional C preprocessor macros to simplify operations on the format of the heap:
- GET_SIZE(p) returns the size of the block with the block pointer p.
- GET_ALLOC(p) returns the allocation status (1 meaning allocated and 0 meaning free) of the block with the block pointer p.
- HDRP(bp), for a
given pointer bp for a block, returns the
address of the header for that block. The header is
always located in the
word
preceding that block. - FTRP(bp), for a
given pointer bp for a block, returns the
address of the footer for that block. The footer is
always located in the
word
following that block. However, note that, given the bp pointer into that block, using HDRP(bp) gives the address of the header for that block, and then using the size given in that header, the address of the footer can be determined.
As noted above, the macros GET_SIZE() and GET_ALLOC() return, respectively, the size and allocation status of the block at address p:
#define GET_SIZE(p) (GET(p) & ~(DSIZE - 1))
#define GET_ALLOC(p) (GET(p) & 0x1)
The expression in GET_SIZE() gets the value of the entire word at address p and then uses the & operator to zero out the bits that will always be a 0 due to alignment (including the least significant bit that is instead used to store the block's allocation status). The expression in GET_ALLOC() gets the value of this word and uses & to extract just the allocation status itself.
The mm_malloc Function
The mm_malloc() function is used in this memory allocator to allocate memory (in the same way as malloc() is normally used). The mm_malloc() function is passed size, the number of bytes to be allocated.
This code first calls find_fit() to search the free list to find an existing free block large enough to handle this new request. If no existing free block large enough was found, then mm_malloc() calls extend_heap() (discussed above) to allocate sufficient new total memory to handle this request.
Finally, this code (and other code in mm.h)
calls place() to place
a block of the
given size at the beginning of an existing free block,
splitting that existing free block into an allocated block
(of the given size) and the remainder as a new (smaller)
free block.
Existing Memory Address Alignment Constraints
In the existing code for mm_malloc(), the size asize to actually be allocated is determined in order to accommodate:
- size, which is the number of new bytes requested (the argument that was passed to the mm_malloc() function), and
- DSIZE the size needed for the block's header and footer.
In the code, asize has also been rounded up
to the next multiple of DSIZE. In particular, to
compute asize (adjusted
size) as
size rounded up to a multiple of
DSIZE, the existing code in
mm_malloc() does:
/* Adjust block size to include overhead and alignment reqs. */
if (size <= DSIZE)
asize = 2 * DSIZE;
else
asize = DSIZE * ((size + DSIZE + (DSIZE - 1)) / DSIZE);
The if
part of this code simply
creates a minimum adjusted size asize of
2 * DSIZE (one DSIZE for
the header and footer, and one DSIZE for the
minimum data size in the block). The else
part of this code (for larger values of size)
computes the adjusted size asize to be the
original size, rounded up to the nearest
multiple of DSIZE, plus another full
DSIZE. To see how this works, we can rewrite
this expression as the equivalent:
asize = (DSIZE * ((size + (DSIZE - 1)) / DSIZE)) + DSIZE;When we divide by DSIZE here (using integer division), if we had first added a full DSIZE rather than DSIZE - 1, the overall final effect would have been to have added 1 to the result, since of course DSIZE / DSIZE is 1. But this expression instead adds DSIZE - 1. The overall final effect of this is to push this sum up to, but not over, the next multiple of DSIZE before then dividing that sum by DSIZE (using integer division, with any fractional part after the division thus discarded). This way of rounding up is a common idiom in systems (and other kinds of) programming.
By rounding size up based on DSIZE to create asize like this, every allocated block of memory is always aligned on an address that is a multiple of DSIZE.
Revising the Memory Allocator's Address Alignment
This memory allocator code is based on CS:APP and was originally written for a 32-bit address CPU. The intention when this code was written was to align the addresses of all allocated blocks of memory on an 8-byte address boundary. But, when run on a 64-bit CPU such as on CLEAR and rounding up size based on DSIZE as discussed above, the result is 16-byte alignment rather than just 8-byte alignment as intended.
The problem
in the code is that DSIZE
(as well as WSIZE) is tied to the size of a
pointer, which differs between 32-bit and 64-bit machines;
and that DSIZE is used in the code both for the
size of a header plus a footer, as well as for alignment.
In this lab, you will separate these two different
uses of DSIZE, to achieve the 8-byte alignment
that was intended in this code without otherwise changing
the behavior of the code.
One place that will need some revision to achieve this 8-byte address alignment is in the function mm_malloc(), as discussed above. Consider all of the uses of DSIZE in this code and decide which of them are using DSIZE as the size of a header plus a footer, and which instead are using it just for alignment:
void *
mm_malloc(size_t size)
{
size_t asize; /* Adjusted block size */
size_t extendsize; /* Amount to extend heap if no fit */
void *bp;
/* Ignore spurious requests. */
if (size == 0)
return (NULL);
/* Adjust block size to include overhead and alignment reqs. */
if (size <= DSIZE)
asize = 2 * DSIZE;
else
asize = DSIZE * ((size + DSIZE + (DSIZE - 1)) / DSIZE);
...
For any of these uses that are just using DSIZE for alignment, they should be changed to instead use some new, different alignment constant that is not tied to the value of DSIZE or WSIZE or anything else that is tied to the size of a pointer.
Similarly, consider the use of DSIZE in the GET_SIZE() macro:
#define GET_SIZE(p) (GET(p) & ~(DSIZE - 1))Is this definition of GET_SIZE() using DSIZE as the size of a header plus a footer, or is it instead using it just for alignment?
Also examine the use of DSIZE in the function place() and determine if this is using DSIZE as the size of a header plus a footer, or if it instead using it just for alignment:
static void
place(void *bp, size_t asize)
{
size_t csize = GET_SIZE(HDRP(bp));
if ((csize - asize) >= (2 * DSIZE)) {
PUT(HDRP(bp), PACK(asize, 1));
PUT(FTRP(bp), PACK(asize, 1));
...
In the same way, also examine the use of DSIZE in the function checkblock():
static void
checkblock(void *bp)
{
if ((uintptr_t)bp % DSIZE)
printf("Error: %p is not doubleword aligned\n", bp);
...
Finally, the existing code, as illustrated in the figures above and as shown in the code for mm_init() below, creates a word (of size WSIZE) containing a 0 at the beginning of the memory block list:
int
mm_init(void)
{
/* Create the initial empty heap. */
if ((heap_listp = mem_sbrk(4 * WSIZE)) == (void *)-1)
return (-1);
PUT(heap_listp, 0);
PUT(heap_listp + (1 * WSIZE), PACK(DSIZE, 1));
PUT(heap_listp + (2 * WSIZE), PACK(DSIZE, 1));
PUT(heap_listp + (3 * WSIZE), PACK(0, 1));
heap_listp += (2 * WSIZE);
...
That extra word is not necessary for achieving 8-byte alignment, since the results from mem_sbrk() are already guaranteed to be aligned. Removing that extra word would change the initial block list layout produced by mm_init() from the original layout shown again on the left, to the new layout shown on the right:

GitHub Repository for This Lab
To obtain your private repo for this lab, please point your browser to this link for the starter code for the lab. Follow the same steps as for previous labs and assignments to create your repository on GitHub and then to clone it onto CLEAR. The directory for your repository for this lab will be
lab-8-implicit-free-list-memory-allocator-name
where name is your GitHub userid.
Submission
Be sure to git push the appropriate C source files for this lab before 11:55 PM tonight, to get credit for this lab.