Methods
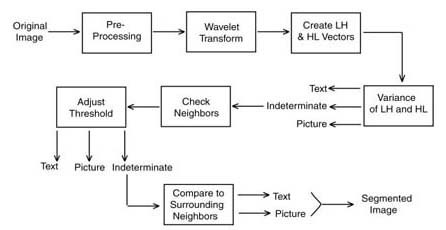
Basic Structure of Algorithm
Used
Our goal is to segment a 512x512 pixel image
into three classes: text, picture, and background. The image is divided
into 256 32x32 blocks, and each of these blocks are classified. If
the 32x32 blocks cannot be classified, the block size is changed to achieve
accurate segmentation.
For each 32x32 block, we transform the block
using a Daubechies wavelet to one level. We make a vector of the
wavelet coefficients in the LH and HL bands to classify the block.
If the variance of this vector is zero, the block is classified as background.
If the variance approaches extreme values, it is classified as text or
picture; otherwise, the block is marked as undetermined.
The undetermined block is then divided into
four 16x16 subblocks. We then try to classify each of these blocks
individually as either text, background, picture, or undetermined.
If the subblock is undetermined, we use context information to classify
the subblock. If the subblock has adjacent text and picture blocks,
the block is at a boundary. Classification cannot be improved by
merging the block with surrounding blocks since the merged big block would
contain mixed types. In this case, we classify the subblock as either as
text or picture. If the subblock doesn't have adjacent text and picture
blocks, we assume that it is unclassifiable because the sample size is
too small. Thus, we merge the eight surrounding 32x32 blocks with
the block and produce a block of size 96x96. The subblock is then
classified according to the variance of the 96x96 block. |