Courtesy of the Audio Tutorial site
Psychoacoustic Model
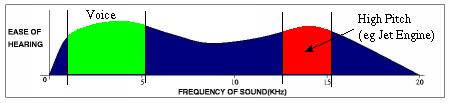
There are two frequency ranges that the human ear is more sensitive to: 1,000Hz - 5,100Hz and 12,500Hz - 15,200Hz. The first range corresponds to the human voice frequencies while the latter corresponds to high-pitch screeches. An example of how the human ear is more sensitive to these two ranges of frequencies is that we are actually more attentive to a baby crying than a washing machine running.
Courtesy of the Audio Tutorial site
The algorithm described in the following is based on this Psychoacoustic Model. First, we performed the DCT. Then, we quantized the signal in three different ways: linear, tangent, and arctangent. Below is a diagram of the quantization "buckets" for the three methods:
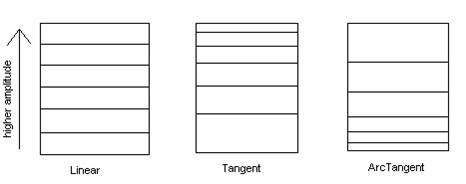
The basic idea is to give more bits to the frequencies in the ranges 1,000Hz - 5,100Hz and 12,500Hz - 15,200Hz. For the linear quantization method, we allocated an even number of bits for different amplitudes. For the tangent quantization method, we allocated more bits for higher amplitudes. For the arctangent quantization method, we did the opposite thing, which was to allocate fewer bits for higher amplitudes.
After we did the quantization, we threw away frequencies that are either below 20Hz or above 20,000Hz since we cannot hear those frequencies anyway. Then, we took the inverse DCT and listened to the outputs.
Here are the original Matlab codes:
Listen to what this algorithm does:
Results:
We were glad that the sound quality
was good for the amount of compression. We were able to compress an audio file
all the way down to about 10% while it was still audible. For audio files that
are less compressed, we would say the sound quality is quite satisfying. We
found that the arctangent quantization method yields the best sound quality.
This, we hypothesized, is due to how the human ear is most sensitive to the
low-frequency human voice. Thus, the more bits we allocate for lower amplitudes,
the better the sound quality.
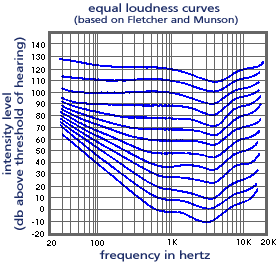
Courtesy of the
Equal Loudness Contours site