Let's review what we have so far. Remember our system model; the input consists of a plucked string suspended on the Dynamat-damped wood pieces and the system is each of the three types of woods that over which the string is suspended instead of the Dynamat-damped control pieces. We found the output of each of the three systems, divided out the input spectrum and obtained the frequency response. While we saw very interesting and significant differences in analysis of the transfer function, we have yet to actually use the data that we found to take our objectives to the next logical step--synthesis.
Here's the situation. We are going to assume that we have a sampled frequency-domain represenation for a very basic (and tonally boring) pluck in the read-only memory of a hypothetical product we are producing. Obviously, we have that data in hand, in the form of our control test using the Dynamat suspension pieces. One of our production goals is to be able to make our product sound like any electric guitar we can possibly measure. For example, let's try to make our generic, boring toned pluck in memory sound like a full and interesting note from a guitar made of expensive ash.
Keep in mind we would like the capability to have our product sound like a whole bunch of instruments (the user would select which one (s)he would prefer), and there are many notes that need to be available for each instrument. Assume that we don't have infinite amounts of ROM memory available for our product and thus a design desicision must be made. Therefore, we'll use an somewhat coarse approximation of the transfer function of ash and apply it to the control and see if there is any audible reduction in the quality of the output as compared to the original ash sound.
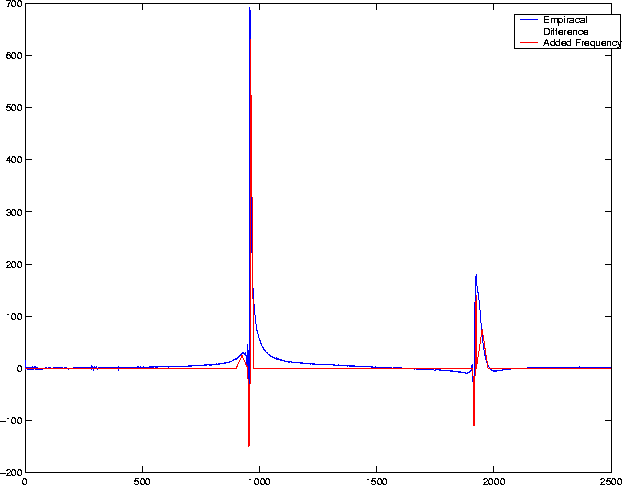
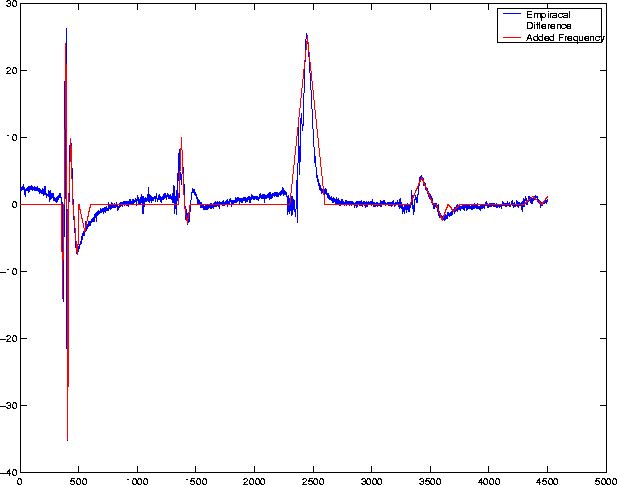
In pursuit of this objective, we will need to calculate what frequency content we will have to add in to make our control note sound like a note from a guitar made with ash. To do this, subtract the frequency-domain representations of the control from that of ash to determine the difference between the two; this is what our product will have to add back into the single boring note in memory if the user selects "ash" as the tonality of the sound.
To make a coarse approximation, we made a Matlab m-file (triproduce.m) that will construct a vector with isoceles triangles that will approximate the frequency spikes of the difference. Though the spikes in the difference vector look somewhat triangular, the approximation will remain crude, indeed. We constructed a vector that is a sequence of these isoceles triangles with strategically devised heights and placed in strategically devised locations along the vector. Since the digital frequency domain representation is periodic, we used another m-file (mirror.m) that flips the vector horizontally and then add them together to get the appropriate periodicity in the added frequency content. Note that this is a far, far less complex represenation for the original difference vector, and thus would be far smaller to store in a memory chip.
Then (and whenever the user selects this note from this instrument), we added the coarse approximation frequency content back into the boring-note frequency information. After using the ifft(...) algorithm from Matlab and taking the real part of it, we wrote the synthesized .au-format file to be compared with the original recording of the ash note. Note that besides a difference in volume and a slight difference in duration (both of which can be eliminated easily), the two notes are indiscernable, and we saved a lot of memory space by using only a coarse approximation.
A design problem solved with DSP!