
And here we are! From left to right: Herm, Courtney, Shermay, and Tracy!

Courtney was asleep, and Shermay was in Hong Kong during our group picture!
Check out the class homepage at http://www-ece.rice.edu/~richb/elec431.html
Our project was to develop a speaker identification system on SGI Indys using record function. Some initial examination of the spectrums led us to believe that we could look at the FFT of the speech signal and pick characteristics from it, as long as the signals were of relatively constant pitch, like vowels. The next question was how to process the signal. The problem of mimicking voices highlighted several other problems with human voices.
The final system we implemented, takes a 2 second voice sample ( the vowel "A"), analyzes the frequency components, and make a decision based on a predetermined set of criteria. The system only attempts to identify the four group members, while strangers should not be positively IDed. The system also made sure the signal was valid and did not clip.
Due to the sampled nature of our data, we are inherently windowing our signal. Furthermore, we then chop out the middle second of the data to remove any start and stop transients. This is exactly like windowing our signal with a box window, the worst possible window-type. The box-window in the time domain is a sinc in the frequency domain, and effectively smears the data. This widens peaks, and deemphasizes features of the frequency spectrum as shown in the first graph.
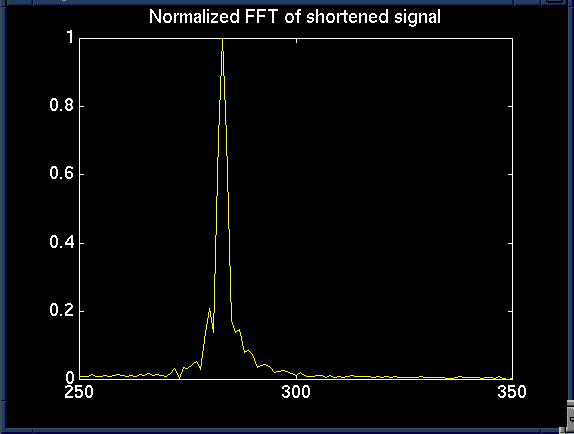
To compensate for this effect, we chose to multiply our data by a nicer window to try to lessen the smearing effect. First, we investigated many window types such as Blackman, Hanning, Hamming, and many others. Some windows more effectively sharpened peaks, while others lessened side-lobes.
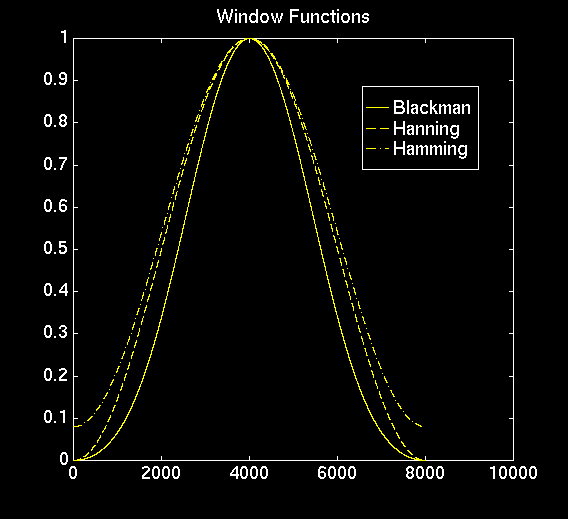
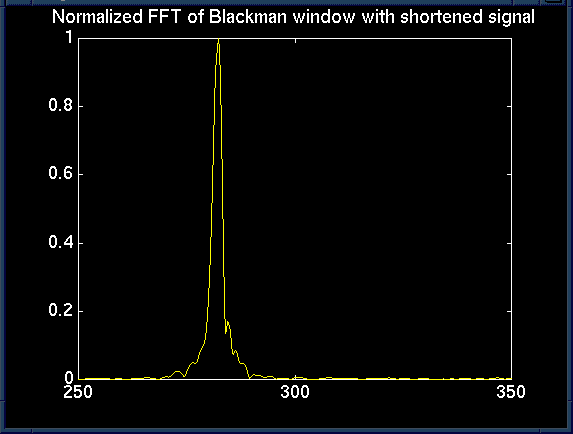
We finally settled on a Blackman window, but many had relatively the same effect. The Blackman window is a good compromise in that in both sharpens peaks and reduces side-lobes. Since our project dealt with correctly identifying peaks and their magnitudes, we felt this was a good choice.
One of the first functions we wrote was a C mex function for recording audio on an SGI. Matlab already has support for playing audio, but the only way to input audio is by reading sun mu-law files with the auread() command.
The record function allows the user to directly sample audio into matlab at any supported bit or sample rate. In addition to the convenience of not having to convert/import data from files, recording directly into matlab overcomes the 8-bit mu-law limitation. For example, for our project, we sampled at 16-bit 8000Hz.
In addition, the function waits for the signal to surpass an preset threshold value. This allows your matlab program to wait for audio input before progressing. The record function, with source and compiled mex file are also available here as record.tar.gz
Another necessary function locates the local maxima of a data series. In our analysis, we require the isolation of peaks of a frequency spectrum for comparison. The C mex function peak2 attempts to extract the local maxima from a set of data. The matlab function peak then extracts frequency-independent information from the original signal. peak() calls peak2() to locate the first major peak. It then checks the data at the harmonic multiples of this original frequency. peak() returns the magnitude of each one of these peaks.
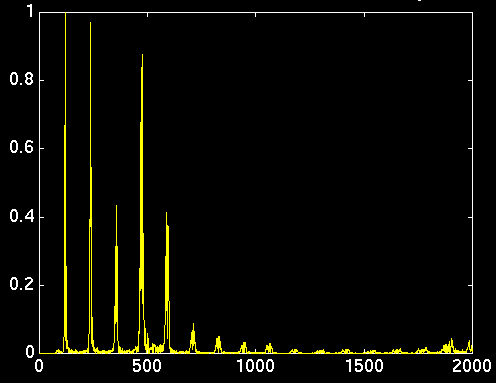 Typical Voice Spectrum
Typical Voice Spectrum
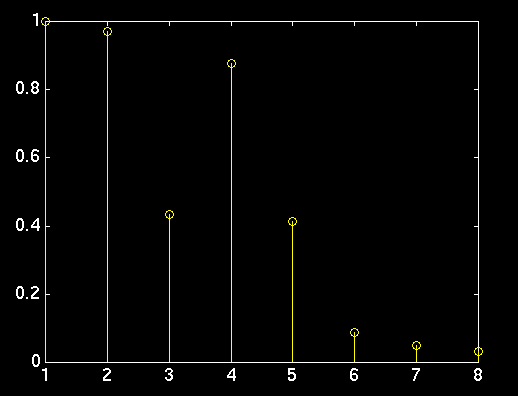 Peak() Analyzed
Peak() Analyzed
As you can see, the peak() analyzed version removes all frequency dependence, and leaves you with just the number of peaks, and their magnitude. This allows us to compare voices at any pitch, as long as your actual "voice" stays relatively constant.
Both of these functions are available with source and compiled mex file in peak.tar.gz
Main program
The main source for our program is available as test.m Also, loadvoice.m must be run prior to test to correctly load all voice responses.
In an attempt to determine which characteristics could be uniquely mapped to one of the four in our group, we first ran six trial runs. Each of us spoke the vowel "A," and we found all of the peaks in each run. The results of these trials are shown below. The x-axis is the number of the peak, and the y-axis is the magnitude of the peak normalized to one.
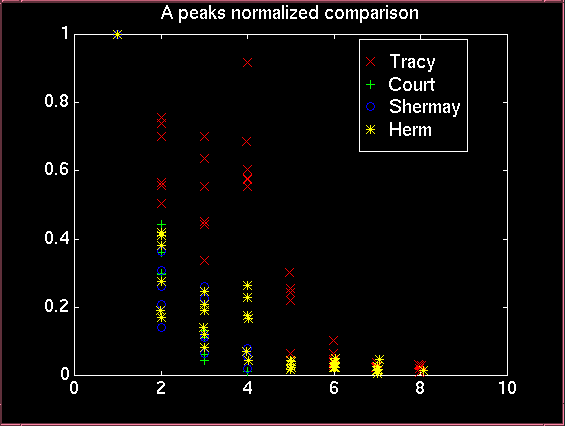
From this graph, we then took the average of all of the runs to get a general idea of what each person's spectrum looks like. Again, the x-axis is the number of the peak, and the y-axis is the magnitude of the peak normalized to one.
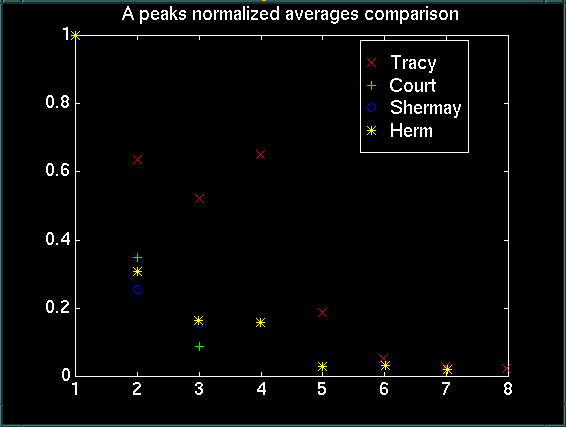
From here, we made the following generalizations:
We coded these simple tests and continued to run experiments, making test cases whenever necessary.
The following chart shows the initial flow chart for the tests. At this point in the analysis, we determine whether the signal was too loud, too quiet, or too noisy, a boy's voice, a girl's voice, or if the signal was unable to be identified.
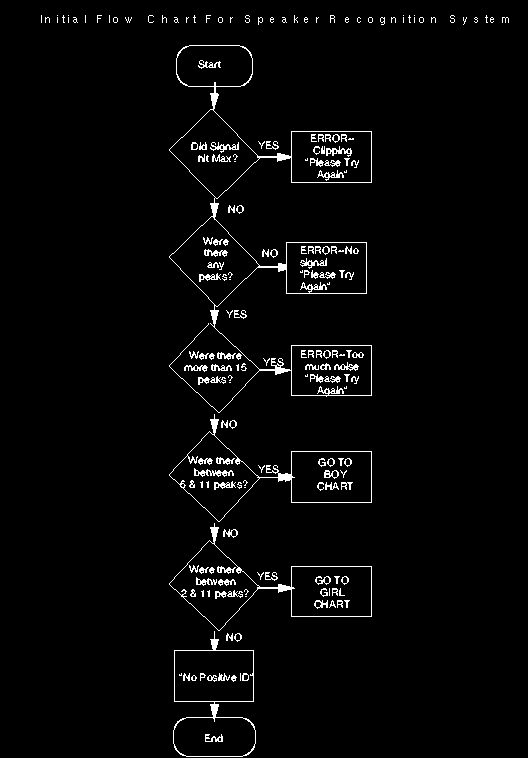
Once the signal was determined to be either a girl's voice or a boy's voice, we ran a series of tests on the peaks to attempt to pin down the actual speaker or reject imposters. The following flowcharts describe the various tests.
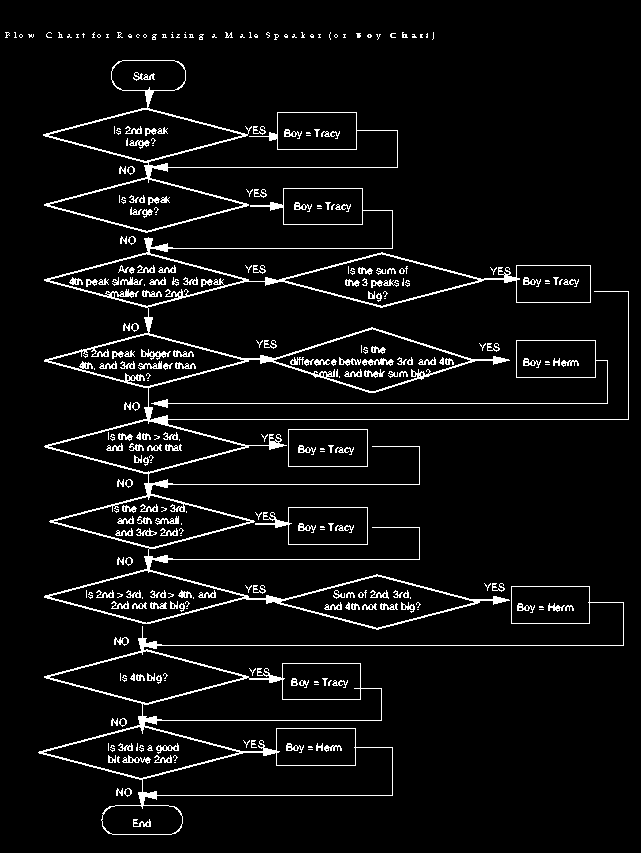
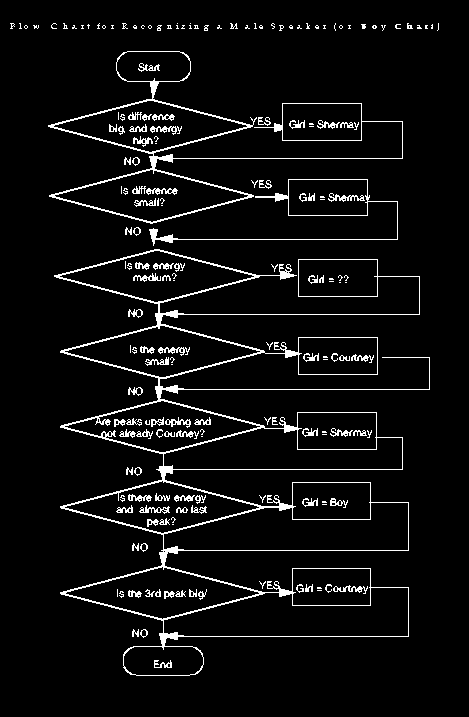
You can download these three flowcharts in postscript form as charts.tar.gz
To evaluate the performance of our system, we ran many trials (ask our classmates). We wanted to minimize both false-identifications, as well as no-positive-identifications, although we definitely preferred the later. After gaining confidence in our system, we had each member run 25 trails of the system and record the results. In these graphs, C indicates a correct identification, N a no-positive-id, and F a false-identification.
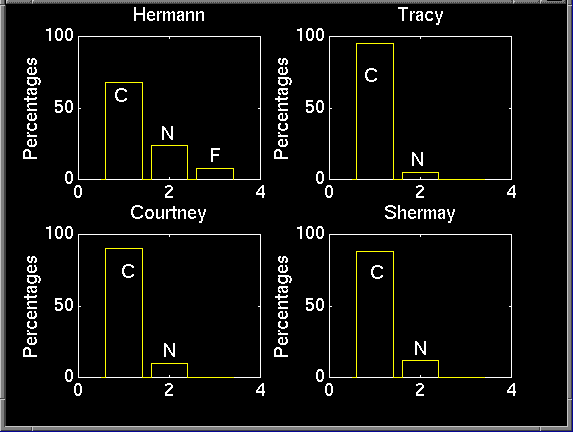
As you can see, the system performed reasonably well. Hermann was the only one able to register a false-identification, and the other had only a few no-positive-identifications. Combining all these results, the system was correct approximately 85% of the time:
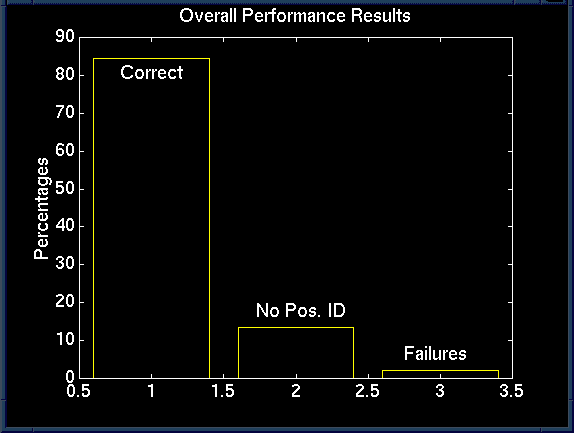
When doing these trials, we found the one could often train their voice over the length of a run. Furthermore, some members would also "mimic" other voices, unintentionally, of course. To remedy this situation, and to also simply gather more independent data, we decided to perform a random trial. We had matlab generate a random sequence of people, and had them run the test in that order. This way, people could not as easily train their voices, or depend on who went before them. The results were relatively the same, with a few more no-ids and less false-ids.
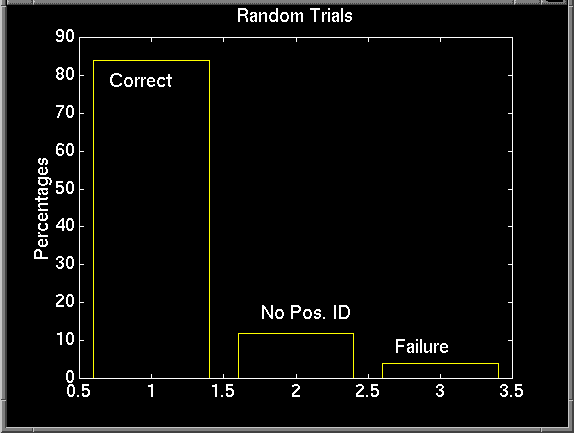
One of the original difficulties our project faced was the problem of mimicking voices. Could someone mimic the characteristics that we chose as our criteria? Well, in short, yes. In fact, we had troubles from day to day with people's voices. One member became sick, and the frequency spectrum of his A's changed. The problem became a fine balancing act: Could we keep the criteria sufficiently tight to reject non-members while still accepting members when they got sick? No, the changes were too great. This brought to light certain other charactertistics of the human voice. People have more than one "kind" of voice. Singers have different voices, like chest voice and head voice, and each voice may have different frequency characteristics. Voices also change with stress. The audible signs that someone is under stress affect the speaker's frequency spectrum. These changes would tend to affect the identification system. In general, accounting for the changes just within our group's voices was our number 1 concern.
The task of identifying speakers based on the frequency components of their voices was a complete success. Really and truly, A+ material.
Here is everything you need to run our project: spkrid.tar.gz. Remember, you need an SGI unless you rewrite record!
Questions? Comments? Write us at dspgroup@sal.jones.rice.edu