In this project, we were succesfully able to carry out vowel recognition through the analysis of formants. Before we proceed with a demonstration of the steps to our process of vowel recognition, here is a very brief description of formants.
The main distinction between vowels and consonants is that vowels resonate in the throat, while consonants are made by blocking and restricting air flow with the tongue, lips, and jaw. Consonants also resonate in the nasal passage (vowels do too, to a small extent, but that can be ignored in simple models). The time-varying system that is the vocal tract of a person speaking can be approximated by piece-wise time-invariant systems. In particular, a vowel can be modelled with the following system: A series of pulses (generated at the voice box) passes through a filter (the vocal tract) that is essentially a pipe. More precisely, a series of linked cylindrical pipes. (The throat is actually made of cylindrical pieces of cartilage interconnected by a dense layer of musculature.) This system is determined using an autoregressive model.
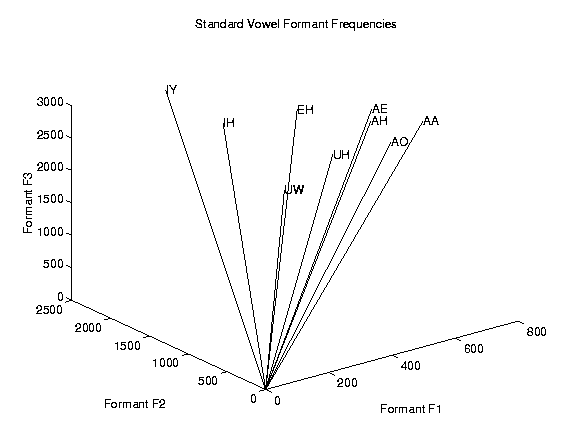
Formants are exactly the resonant frequencies of your vocal tract when you are pronouncing a vowel. Most adult males have a fairly similar frequency range for formants for given phonetic vowels. In our project, we record a word, manually extract the portion of the signal corresponding to the vowel, and calculate its first three formants. The program determines which phonetic vowel was pronounced based on a set of formant profiles. Essentially, one can think of the standard formant values in a 3-d plot with axes of first formant frequency, second formant frequency, and third formant frequency. We take the calculated formant values, and match it to the vowel it is closest to. A list of the vowels we check for is here. This also includes our results of vowel recognition with basic words. This will be discussed at the later.
{kind=link}
{kind=link}