Two State LPC Vocoder
Encoder
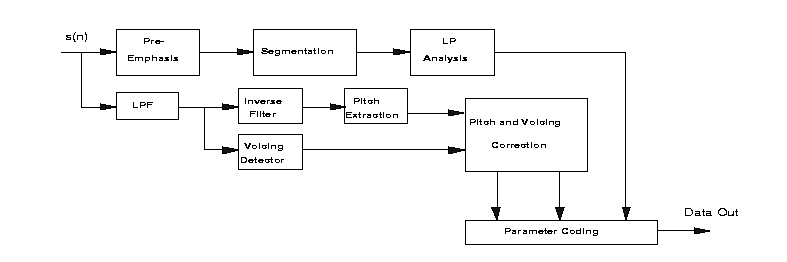
Based on the analysis of the previous sections, the system of our two-state LPC vocoder follows the following block. In the encoder, we first did some kinds of pre-processing which include pre-emphasis, segmentation and windowing. The we did Linear prediction analysis to extract the linear prediction parameters for each block, which include reflection coefficients, alfa coefficients, Gain and prediction error. Then we applied some kind of voiced/unvoiced decision algorithm to determine the voice/unvoiced feature and some kind of pitch detection algorithms to extract the pitch period. Before transmission, the LP coefficients, pitch period, gain and uvdecision(one bit) result were encoded. For simplicity, we here only discussed the quantization feature of linear prediction coefficients.
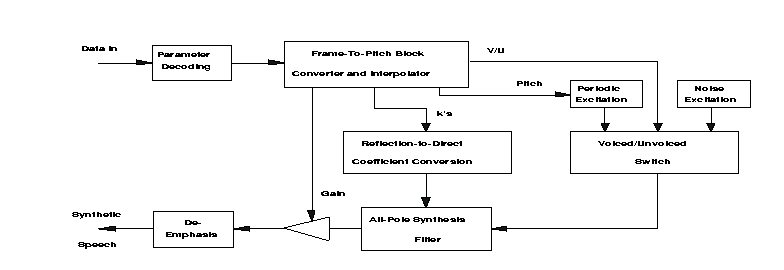
Based on the simplest two state speech production model, the decoder is as the following figure shows. Unvdecision is a switch to determine whether the excitation should be white noise or an impulse train with pitch period. The reflection coefficients were conversed to direct coefficients as the parameters of the all-pole inverse filter. Gain is used to reconstruct the energy of the speech. Then some post-processing procedures were applied to align the output speech.
For a two-state LPC vocoder, the system block is almost fixed. What makes difference is the application of different algorithms to do all these parts of work. In brief, there are three big problems, i.e. (1). linear prediction, (2). voice/unvoiced decision and (3).pitch detection. So we first set up the framework of LPC vocoder. Then we focused our efforts on different algorithms for each part and carried out comparisons, hoping to derive some insights for future work. The next several sections will discuss these algorithms sepately. To contain all these algorithms, clear interfaces were designed for between modules.
To improve the performance, people will also assume more complex production models(e.g. mixed excitation and residual excitation).Later, we will also propose WRELP scheme. But in general, they can be generalized as some Excitation passes an inverse filter to get the reconstructed speech, i.e. "source-filter" model.