The analysis of the speech signal is always the foundation of related processing techniques. So we first studied the spectral features of speech signals.
Features of Speech Spectrum
Since speech signal is time-varying, the analysis should be a time-frequency analysis, which is quite different from the context of our
532 course. Review that in our course, we always assume WSS and hope to take length of samples as long as possible to obtain a low-bias. Besides, bias variance tradeoff is always what we hope to control. In speech signal, however, we have to cut the whole signal into blocks to obtain short time stationary. Typically the block is 20-30 ms long. Short-time FT (STFT) is applied in the spectral analysis for speech.
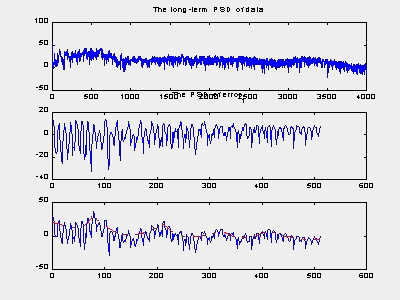
Fig. 1. Long-term spectrum vs. Short-time spectrum. (a). shows the long-term spectrum. (b) is the predictor error spectrum; (c) The red line is the AR model spectrum, and the blue line is STFT of one block.
To test this, we did a bunch of experiments to draw the different spectrum of speech. We found from the results that long-term spectrum is non-sense for speech. The short-time spectrum is quite well fitted by AR model and gives us a good structure to represent the signal. Spectrogram is applied to show the time-varying feature of speech spectrum. To make it numerically clearer, we also show the 3-D mesh graph here.
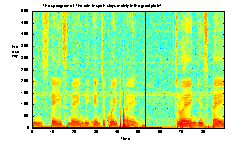
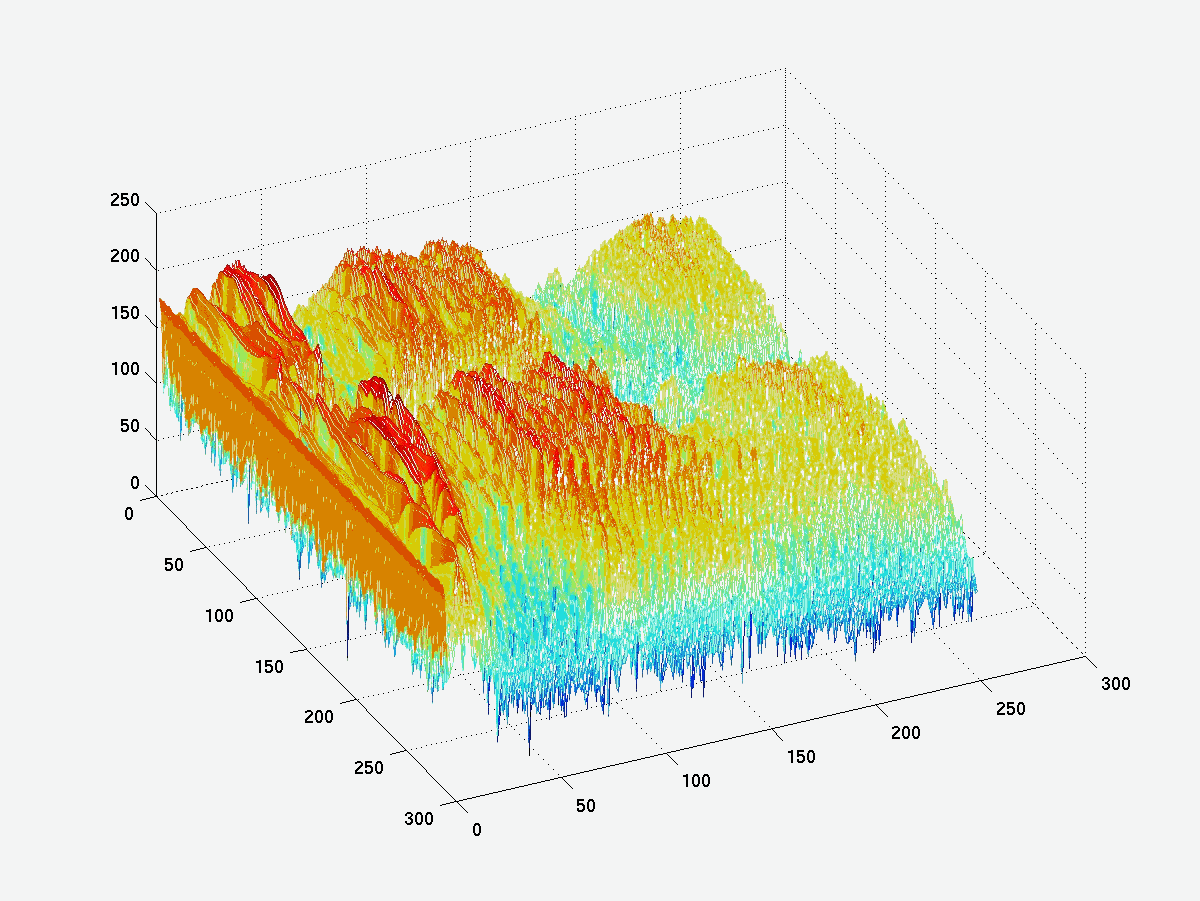
Fig, 2.The spectragram style Fig,3. The 3-D mesh style
Voiced/Unvoiced Spectrum
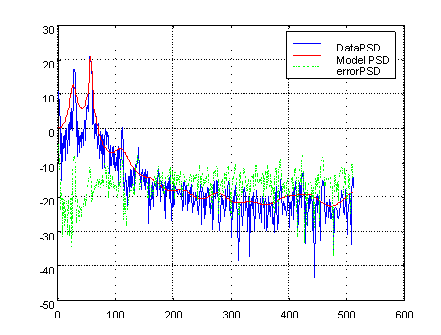
Speech can be generally divided into voiced and unvoiced. We studied both the spectrum of typical voiced and unvoiced block. The spectrum in Fig.4. shows that for a voiced speech, the time series have obvious periodic. The spectrum of voiced speech is featured as some fine spectrum with formant envelope. The fine peaks mean the pitch period and the formants reflect the vocal tract feature. While for the unvoiced case, the signal looks much like a white noise. The spectra lose the pitch period but keeps some formant peaks.

Fig.4. The spectrum of Typical Voiced/Unvoiced Segment
This figure shows that the AR model fits the speech signal quite well. By passing the speech through a predictor filter A(z), the spectrum is much more flatten (whitened). But it still containes some fine details.
Speech Production Model
The study of human vocal apparatus has shown that speech is simply the acoustic wave that is radiated from the vocal system when air is expelled from the lung and the resulting flow of air is perturbed by a constriction somewhere in the vocal tract. Specifically, the production model can be formulated as the following;
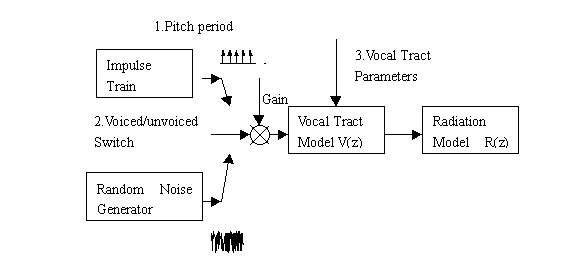
This block diagram assumes the simplest production model of speech. Voiced speech is produced by taking impulse train as excitation. In unvoiced segments, a random white noise is used as the excitation. Then the excitation goes through a vocal tract model V(z) to get the output speech. In the context of linear prediction, this tract model is fitted by a AR model inverse filter 1/A(Z). In the real world, a radiation model R(z) is also considered. But for simplicity, this R(z) is always omitted.