COMP 405
|
Cloud Computing and the Google App Engine |
|
|
In general, a cloud computing service provides hundreds of thousands of equivalent servers that are leveraged to enable applications to achieve the following capabilities:
See pictures and descriptions of the data centers that house cloud computing services: Google, Microsoft, Amazon
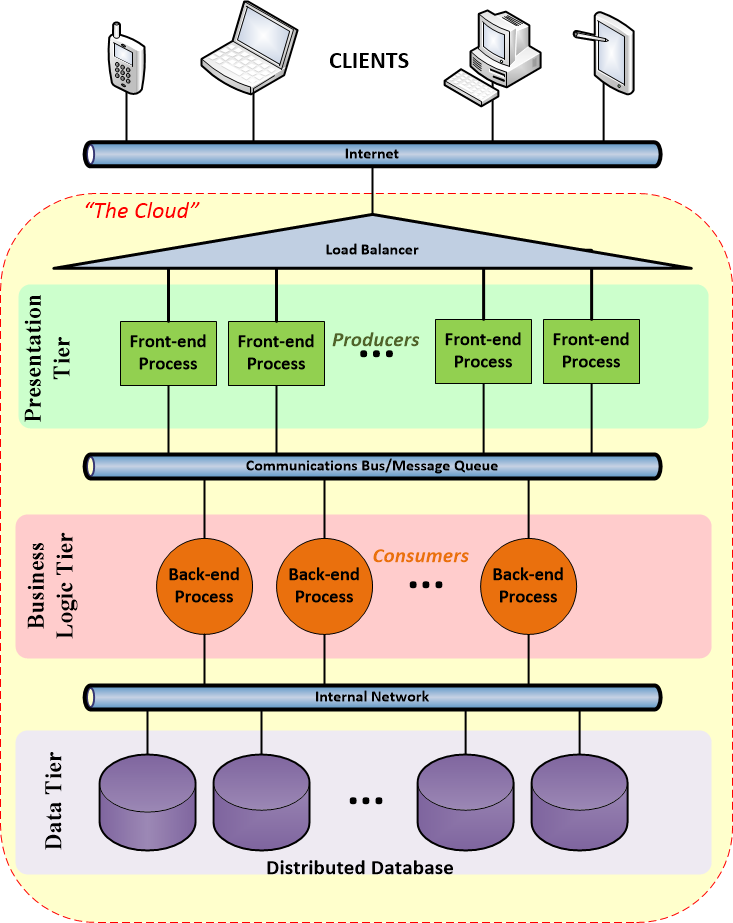
Different cloud computing providers use slightly different approaches but a typical architecture a modification of the classic 3-tiered system architecture:
Here, in the spirit of MVC, the user-centric portion of the system is sectioned off from the main "business logic" processing portion. In addition, the data storage sub-system is also decoupled from the rest of the system. In a strict 3-tier architeture, the database (data tier) is encapsulated behind the business logic tier so the presentation tier has no direct access to the data storage. In most cloud systems, however, the front-end processes of the presentation tier can directly access the data storage for tasks such as user management.
Most cloud systems are optimized to be able to easily create identical clones of different processes. Processing is spread over all the cloned processes and the processes can be spun up or spun down to match the current processing load requirements. This is called "elasticity". Hence, cloud system use front-end load balancers/routers to spread the incoming requests, e.g. web page retrievals ("GET"), form postings ("POST") or direct web service interactions, from the clients across the available front-end processes.
The front-end processes prepare the request to for further processing by the back-end processes. Typically, the front-ends perform tasks such as data validation, permissions checking, etc. Note that if the interaction with the client requires more than one request, state-ful information about the "session" with the client must be propagated across all front-end processes because the load balancer does not guarantee that the next request from the client will go to that same process. The next request from the client may be routed to a different process instance on a different machine on a different side of the world! Cloud systems provide infrastructure services to make these sorts of tasks as transparent as possible.
It is very common for web servers to instantiate a new request handler for every request coming in from a client or perhaps to "reuse" request objects for subsequent requests. In general, do NOT assume that values will persist between requests! Likewise, do NOT assume that values will automatically be destroyed between requests either!
Read about more about Servlets, a Java technology for web application front-ends.
Most cloud systems are geared towards using a producer-consumer model for transfering tasks from the front-end to the back-end. Once again, there may be multiple identical back-end processes to match the current overall processing load. Instead of a single producer paired with a single consumer waiting for the producer's output, the multiple producing front-ends all queue their tasks in a common messaging queue. When it becomes available, a back-end process simply pulls the next task from the queue. The back-end processes are thus decoupled from the front-end processes. It should be noted that cloud systems typically do provide other communications modes for interprocess communications which can be useful in some situations. But the goal of most cloud applications is scalable processing which the distributed producer-consumer model serves well.
Typically, it is the back-end process that makes the most use of the data storage sub-system. Since the processing units of an application may be spread across the globe, a distributed database system is needed. The goal of the cloud infrastructure however is to minimize how much any application has to worry about the synchronization issues for a distributed system and simply make the data storage and retrieval as transparent as possible. Typically, while the database may not be physically co-located with the processing units, access to the data storage is provided as infrastructure services to hide the distributed nature of the system.
In addition to the traditiona SQL relational database systems (RDBS), cloud services also often offer schema-less "NoSQL" data storage capabilities. These systems are optimized for high-speed storage and retrieval of huge numbers of simple objects that have simple relationships between them. This makes them ideal for use with Object-Relational Mapping (ORM) frameworks that help bridge the gap between the objects in an OO sytem and the Entity-Relationship (ER) models of RDBS.
| Google App Engine | Microsoft Windows Azure | Amazon Web Services/EC2 | |
| Application level framework | Specialized Java and Python apps only | Apps are running in an accessible OS | Apps are running in an accessible OS |
| Supplied Operating System-based | Not available | Apps run in specialized Windows Server OS | Specialized Amazon OS available |
| Custom Operating System-based | Not available | Can run Linux and Windows OS images | Can run custom OS images |
| Strength areas | Lots of small decoupled operations | Large.NET-based applications, state-ful request processing |
Migration of traditional server-based applications,
state-ful request processing |
Additional articles comparing the different cloud providers:
App Engine is Google's clound computing service. It is a request-processing-centric model where an "app" is is essentially a function that is called to service a web request from a client. GAE supports Java, Python and Google's own Go language development. In Java, requests are serviced by Java Servlets, which are objects that conform to a specific calling interface. An "application server"" translates the web protocols used by to communicate to the server into a method call on the servlet. GAE provides this application server infrastructure plus the automatic scaling capabilities to utilize the huge computing resources of their cloud system.
GAE automatically scales up and down the number of servlet objects that are available to process web requests in order to maintain a reasonable response time for processing those requests. These servlets may or may not be spread across multiple machines and data centers. Due to its request-processing orientation and to maintain performance, GAE imposes a 60 second time limit on front-end request processes. Back-end processes can be either "task" object instantiated and queued by the front-end processes or persistent background processes that are always running. Tasks spawned by the front-ends can run for up to 10 minutes and persistent background obviously, have unlimited lifetimes.
Billing is by the number of total computer hours across all processing instances plus data storage access counts. Luckiliy GAE accounts are free for anyone and come with a generous quota of free cloud usage.
Google offers 3 types of data storage systems: a traditional RDBS called Cloud SQL, a file system-like storage geared for large entities called Cloud Storage, and a dictionary-like NoSQL system called App Engine Datastore.
© 2013 by Stephen Wong