| Power method |
Introduction Power method Formant Trajectory Cepstrum method Result Conclusions Future work Bibliography |
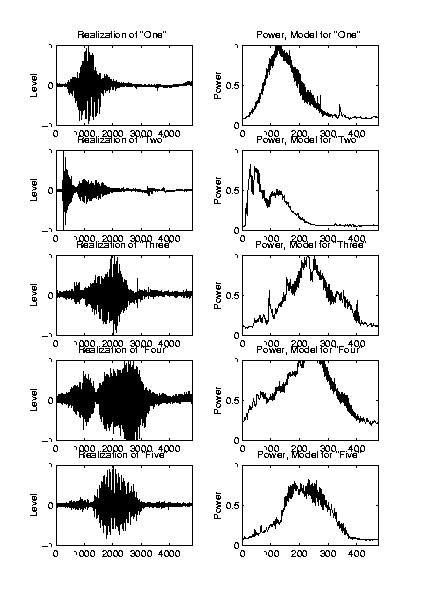
| This method uses the power, or energy, properties of the words for recognition. It is easily implemented since it only requires power computations of the tested words. We will use the fact that words are pronounced different and therefore that the power is distributed different i time. By training a model with several realizations of our words and average together, this will give us a specific pattern for each word that we can compare with the word we are searching for. |
|
The first part consists of developing models for later comparison. For this purpose we used data recordings of three members of our group, namely Daniel, Pam
and Mark. We had 10 recordings of each word ("one" to "five") and each person. That makes a total of 3x5x10=150 word for training the model.
Each realization was windowed with overlapping hamming windows. Each realization being 4800 samples long. For the windows we empirical found the following to be optimal. Windows chosen to 50 samples large, with a 10 sample step between adjacent windows. This gave us 476 windows for each realization. For each window we then squared the terms, summed the squares and took the square root of the sum. The result was a 1x476 Power vector for each realization. The model for each word was then obtained by summing the three members power vectors and averaging over 150. A graph of the some realizations and the model can be found here. |
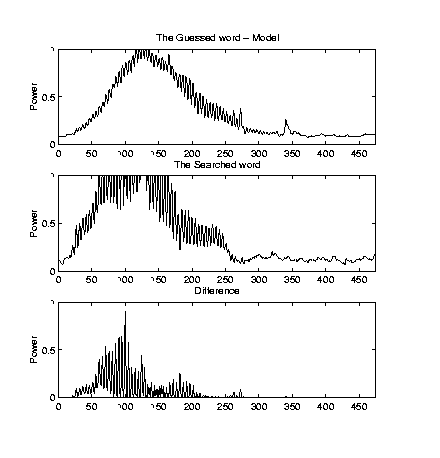
| The identification of an unknown word started by computing the power vector P of the word. We then subtracted the power vector of each model out of P and computed the two norm of the result. The model resulting in the smallest distance was considered to be the best guess for the identification of the word. Here is a graph of the realization of the searched word and the word it is compared to in the model. The word is "One" and also shown is the difference between the model and the word, used in the decision process. |
| All this code was written and tested using Matlab. The file with matlab-code for making the model is called power_model.m. The code for recognizing the searched word: power_find.m. |
| The results obtained with this method are in the Result section. For amelioration of results we tried to shift the unknown word in a way that would line-up the maximum power of the tested word with the maximum power of the model. We found this clever because of the problems of recording every word to begin at exactly at the same time. The idea was to compare the shape of the power-distribution instead of the alignment in time. The error decreased for some members data (mainly for data not used in the model) while it increased for others. However since the overall error increased we decided to ignore this modification of the program. |
| The primary problem with the power method is it's strong dependence on where each recorded word is located in time. This aspect of the model reduces significantly the resemblance between the model and the tested word. This method was able to identify the words "one" and "two" with relatively low errors, but overall it's an inefficient method for recognition. |
{kind=link}
{kind=link}