| we can resolve higher and higher frequencies by placing the microphones closer
together. However, the closer the microphones come together, the more difficult it becomes
to resolve unique angles. Endfire becomes worse as the array radius becomes smaller.
Therefore, the array radius must be large enough to maintain an acceptable resolution
while being capable of processing an acceptable frequency band. One thing that can be
done is filtering out the high frequency content to accept any signal without having
errors due to high frequencies. This is only possible if the signal also has enough low
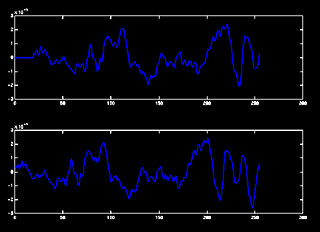
frequency content for us to find it's alignment. The entrance to
Beethoven's Fifth Symphony contains significant low frequency content, which made it
possible to use as a test signal.
Why does this loss of resolution matter?
Loss of resolution is manifested as error in angle measurement. Worse, these small
errors in angle result in large errors in range estimation. The very fact that the sample
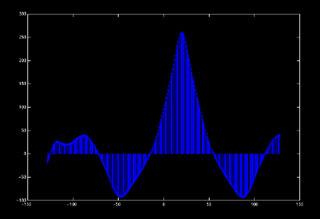
shifts are integers places a restriction on detectable range. For example, with an array
radius of 1 meter (ridiculously large for air, but it shows that even accepting a bad
frequency response doesn't help), a change of 1 sample at the edge of our detectable range
moves the apparent location from approximately 70 meters to infinity.
This effect is the reason why sonar-like systems typically fall into 2 types,
Near-Field and Far-Field. Our system is a near field implementation, which allows the
ability to range up to the previously described limit. If we decided to give up on
ranging, we could have a far-field implementation. The far-field implementation depends on
the simplifying assumption that the signal's angle of arrival to each of our microphones
is the same. (Essentially assuming that the wave-front is a plane wave, rather than a
spherical wave). Unfortunately, it seems that the only way to range in the far field is to
increase the size of the array; which is the same as making the far-field part of the
near-field.
Are the limitations of the 2-microphone system still present in a multiple
microphone system?
The limitations of the two microphone system are present to some extent in any system
with more than 2 microphones. The loss of resolution due to endfire is reduced because we
can always select and use pairs of microphones that have acceptable resolution in the
direction of the signal source. The drawback to this is that we have to calculate the
shifts for all of the pairs before we can know which ones to use. We are, in effect,
throwing MFLOPS at the problem.
The frequency sensitivity restriction still exists, however, because we are still
sampling only once every array radius. This particular problem is the primary reason why
passive sonar-like systems are not used in air. A medium in which sound propagated more
quickly, however, would have much larger wavelengths. In such a medium, a system such as
ours would become workable. In other words, we have confirmed that it works best in the
types of applications in which SONAR is typically used. |