ELEC 301 Final Project: Text Independent Speaker Recognition
Testing System Architecture
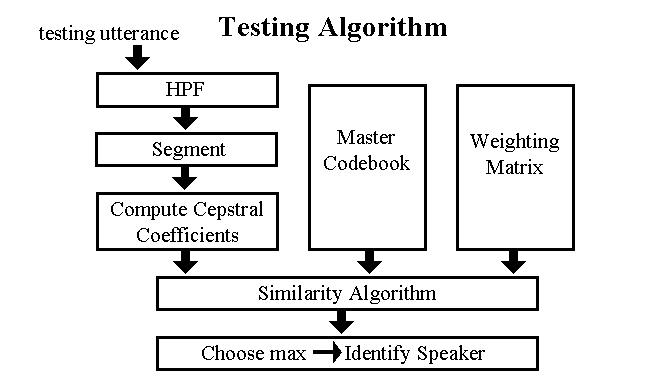
The testing system mirrors the training system architecture. First you analyse the signal, then compare it to the data stored in the codebook. Which ever person has the closest match wins!
First we recorded speakers who had recorded training samples for us. We recorded two testing signals, using the same microphone in the same room as we had in the . One was shorter, approximately 10s, and the other approximately 20s. The text spoken was random reading from books Nils had in his room at the time, a Lincoln Lab brochure, a book of Hymns, etc. The words spoken did not have any designed similarities with the training sentences.
Once we had the sample, we high pass filtered it. We then calculated the first 12 mel-cepstral coefficients with a short window, 10ms, just as we had in the training phase. We also calculated the mean pitch of the speaker, using the same method as in the training phase. These values were stored, without clustering, for the comparison phase.
Comparison PhaseIn the comparison phase, all the pieces of the puzzle come together. A similarity measure is computed according to Kinnunen and Franti [1]. We first computed the distance between each test codeword and each codeword in the master codebook. We used eculidian distance for this. We then took the inverses of these distances, weighted them with the weights calculated in the training phase, and summed the results. This was performed three times, once for the cepstral coefficient vectors, once for the delta cepstral coefficient vectors, and once for the delta-delta cepstral coefficient vectors. This gave us three similarity values.
We also computed the mean pitch for the test speaker.
We then add the squares of each of these 4 measures and take the square root. The person with the highest number value is determined to be the speaker of the sentence.
System
Architecture
System
Architecture