
In the parse case, for example, a scanned image could be parsed with a stray pen mark below or beside a number. This could lead to the glitch being interpreted as a number (in the case where the glitch is part of the Zip Code a number) or as the entire Zip code (in the case where the glitch is below the actual Zip code). The latter case is obviously the more serious of the two because the parse algorithm expects 5 elements to be parsed in and the stray mark is just one element. The former case, where the mark is inbetween numbers of the Zip code, a number is left out because the parsing algorithm reads in only five digits. The glitch is considered a number and so one of the actual Zip code numbers is left out. This causes problems in the comparison stage of the code too because the mark is interpretted as a number and is thus recognized as the number that it resembles most.
Solutions: There are several different ways that we could solve the
problems that noise introduced. We did not implement any of these
solutions due to time constraints and the fact that we were more concerned
with our primary goal (recognition). One possibility is to make sure that
the parsing function ensures that the zip code is a set size. Obviously a
zip code could not be 8 or 9 pixels across so the program would know that
the captured image was a glitch and would parse up from that point.
Another solution would be to have the recognition code efficient to the
point where it would recognize if a character was not a number, and go back
to retrieve the number that would have been read in if the stray mark did
not exist.
Problems were faced when numbers had irregularities in them so that the
hole algorithm did not function as planned.
Hole Algorithm:
When we were trying to tighten our standard
profiles we decided that our code could be a lot more efficient if it
could compare numbers against only a limited set of possibilities, rather
than comparing them to the whole range of possibilities (0-9). We devised
a hole algorithm that determines the
number of holes that a number had in it. Depending on the result, the
unknown number is compared to a particular set that could only have the
particular "hole characteristics" that the unknown number had. For example
if a number has two holes, it is automatically recognized as an 8 because
there is no other standard representation of a number that has two holes.
Other examples are discussed on the hole algorithm page.

In the case of the 6 above, the problem is caused by the fact that the hole algorithm in matlab (bweuler.m in Matlab) uses an euler number method of computing the number of holes. In short this means that it takes the image and subtracts the number of objects minus the number of holes. We then take that and subtract one and take the absolute value to determine the number of holes. The 6 (below left) poses a problem because the hole at the end is too vertical and thus the hole algorithm interprets the top (remove everything below green line) as having two objects and no holes yielding an euler number of two which is wrong. This is opposed to a 6 that gives the correct result (below right). Here the top has one object and zero holes, so the euler number is 1 which is correct (yields zero holes on top). Both cases yield the correct number of holes on the bottom: remove everything above the red line, one object and one hole, euler number equals zero, number of holes on bottom equals one.

The 8 above poses a problem because it has three holes when it is evaluated. There are no numbers in the standard set that contain three holes. The nine poses a problem becuase the hole on the top of the nine is not closed so it is not interpreted as a hole at all. This leads to it being compared against the "no hole data set" which does not contain a 9 so an error is generated.
Solutions: The 8 with three holes was easily corrected. We assumed that
any number with more than three holes was written irregularly so we checked
it against all the possible data sets and matched it to whatever number it
was closest to. The 6 and the 9 problems are still uncorrected. The 6
problem could be remedied by altering our
standardization code to recognize that a hole
was present. Then, depending on where the majority of the hole was, the code
would place the entire hole in that half of the image thereby reducing
error. The 9 problem is hard to remdy until the comparison algorithm is
more precise. As it stand, if a 9 has no hole, it is checked against a
data set with no nine's in it. This is necessary because otherwise the
nine can be confused with a 7 or a 4 depending where the gap lies.
Thinning Algorithm:
This algorithm mainly had problems when a number had too much width. The
thinning function (bwmorph.m in Matlab) tries to recreate the number with a
'minimally connected stroke' that can lead to problems if the image has
excessive width. Take the example below:
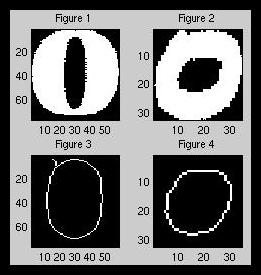
The zero after thinning (figure 3) has a line coming off of the upper left corner which is not supposed to be there. This does not cause a problem in this specific case, but in other cases, it is a potential hazard with certain fonts.
Solutions: We realized, after some trial and error testing, that some
fonts are probably non-standard enough that we would not have to recognize
them in the specific case of zip codes. Addresses can be written in fancy
fonts, but generally speaking the font will probably not be too far from
the ordinary. So we concluded that we didn't have to worry
about these fonts because after all, the post office loses letters too!
 |
Next

|
 Previous
Previous
|